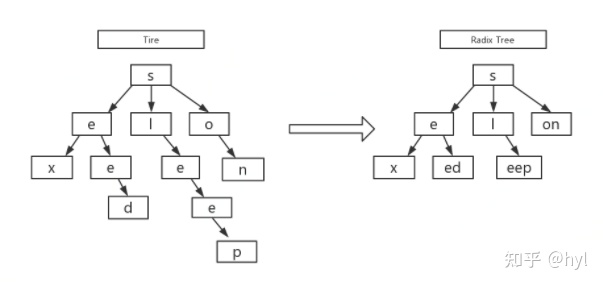
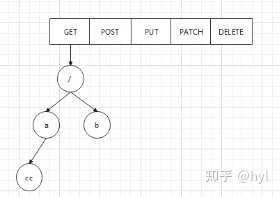
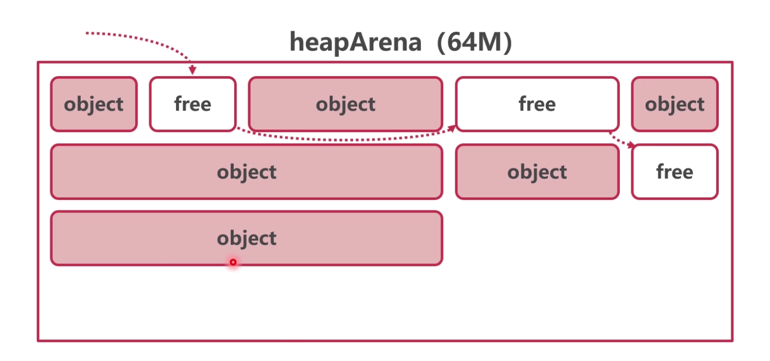
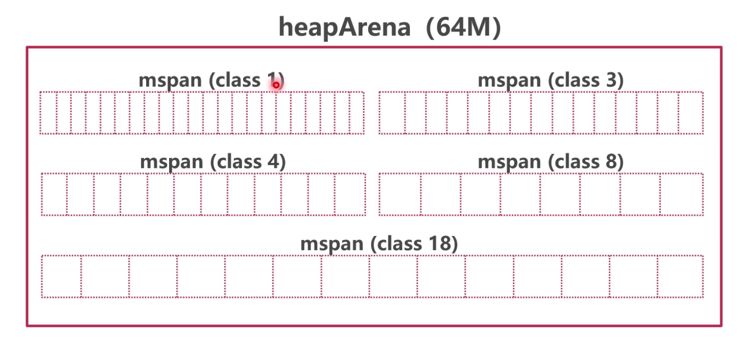
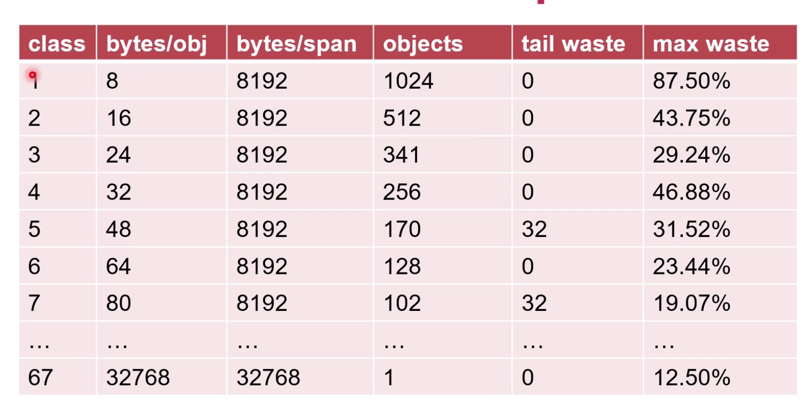
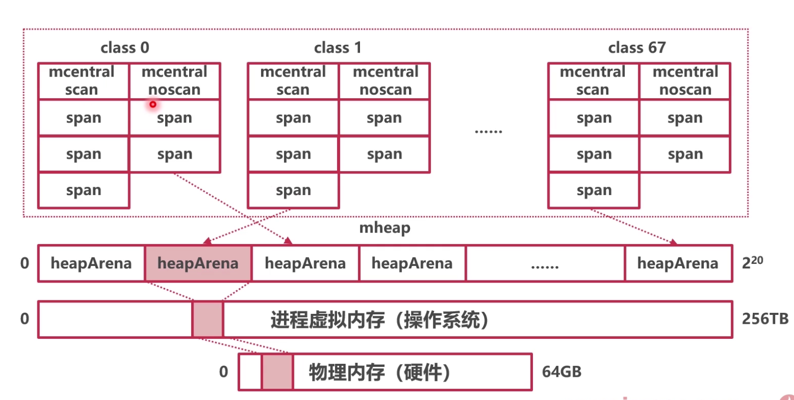
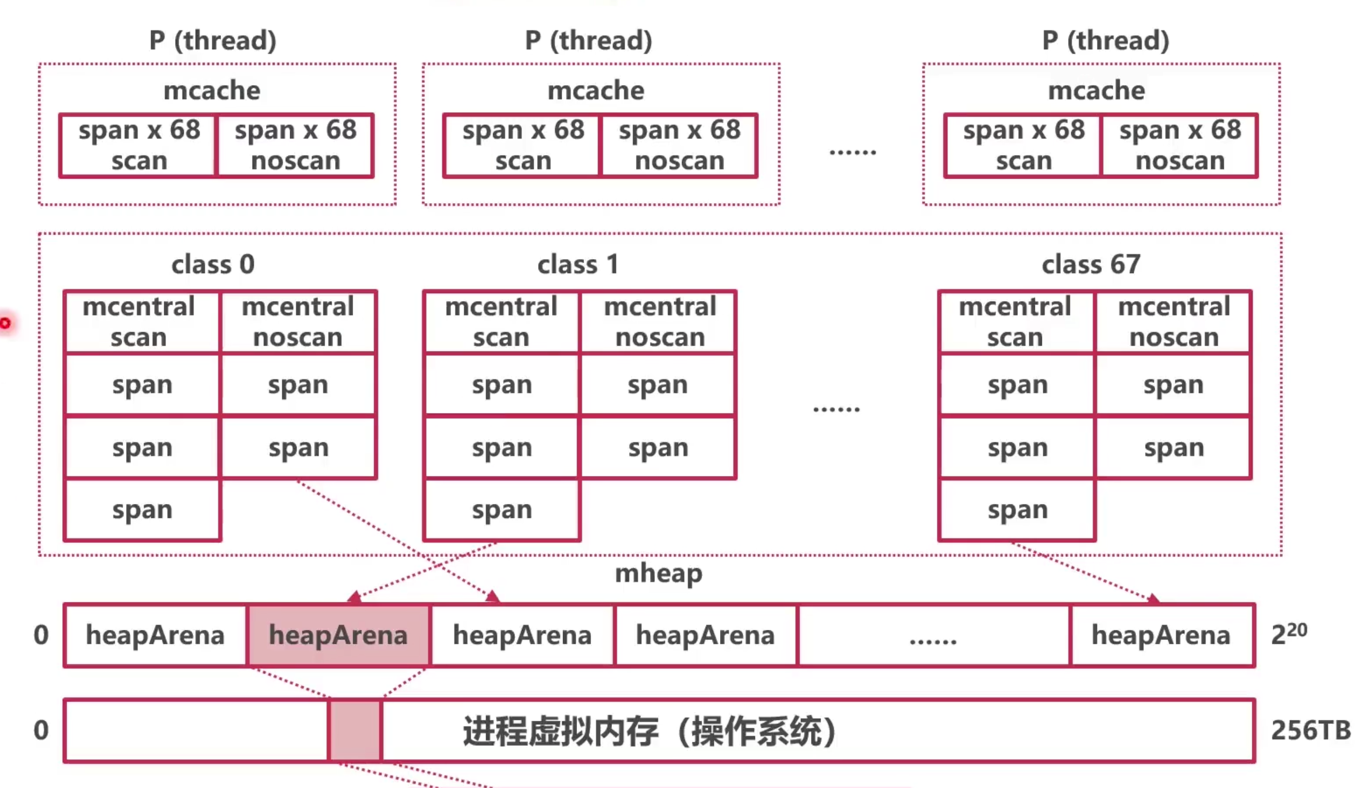
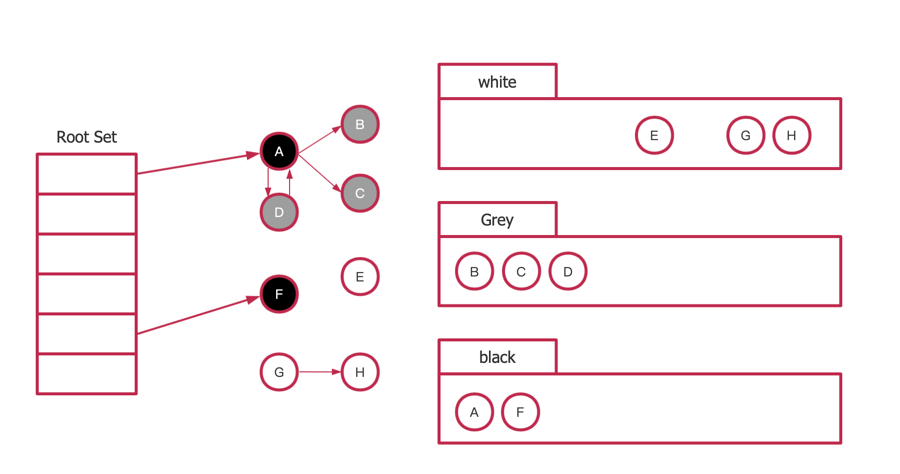
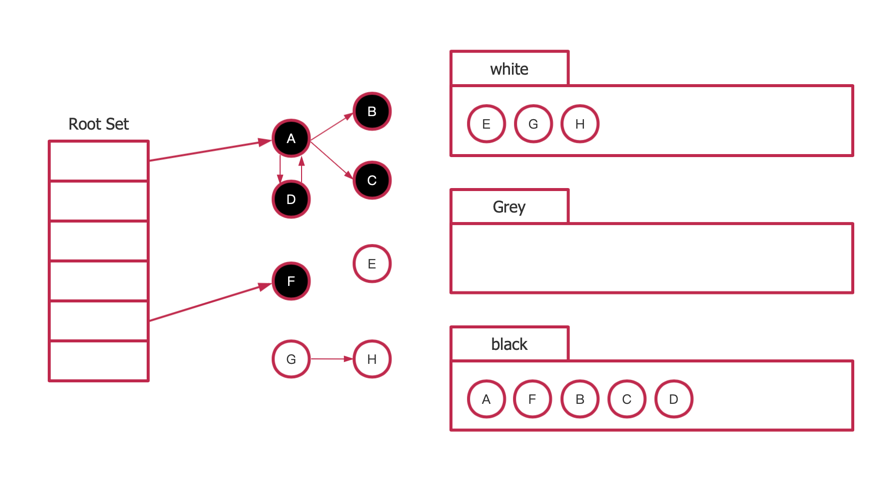
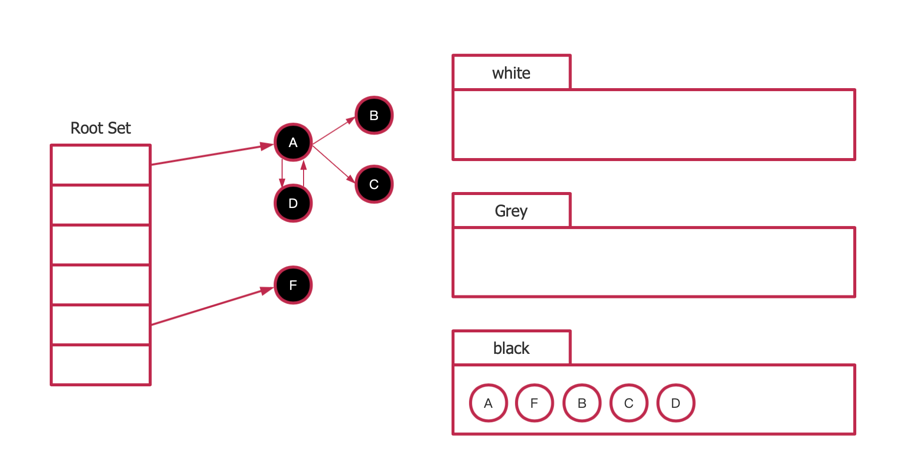
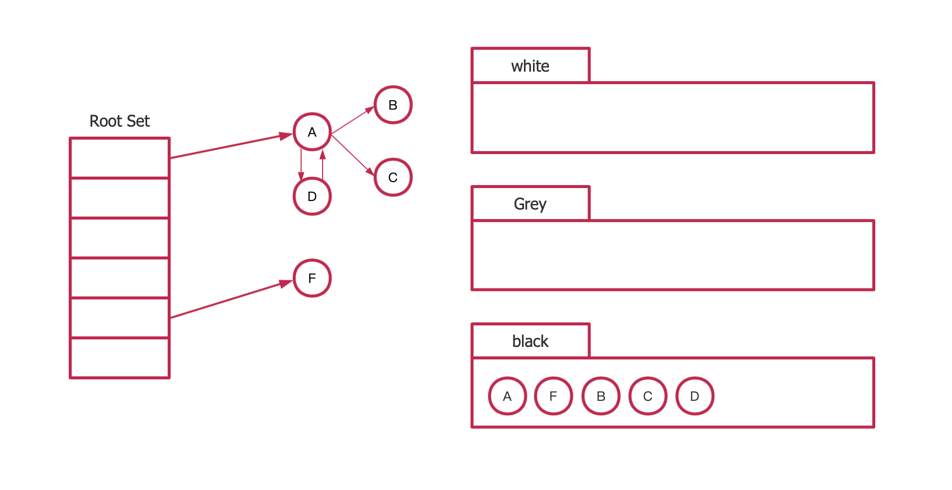
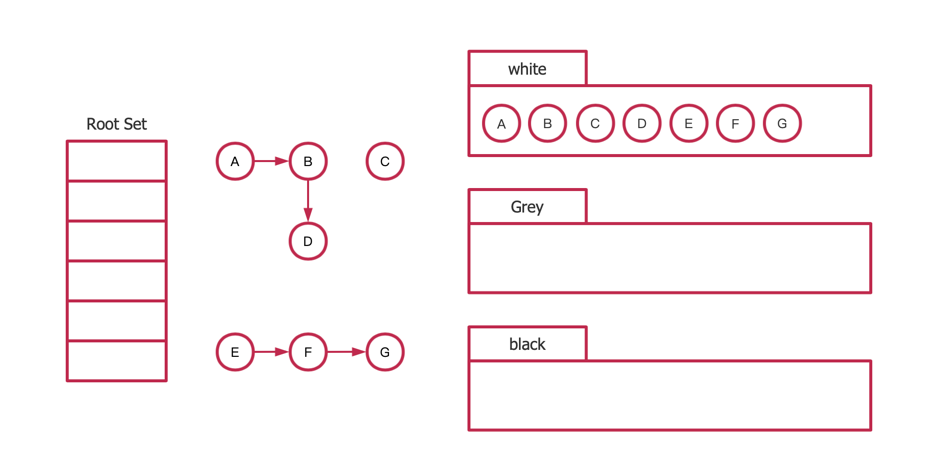
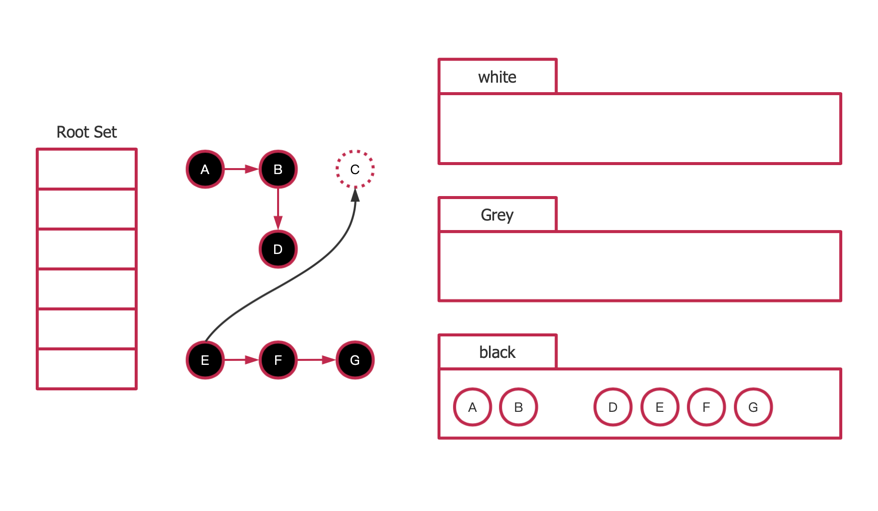
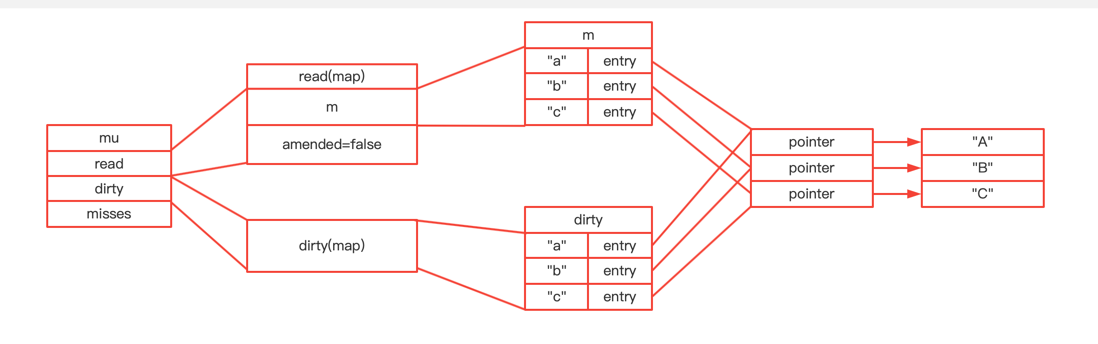
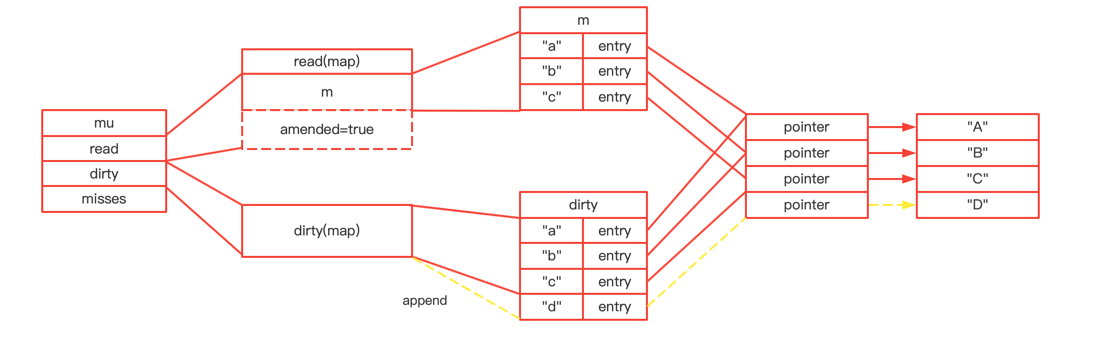
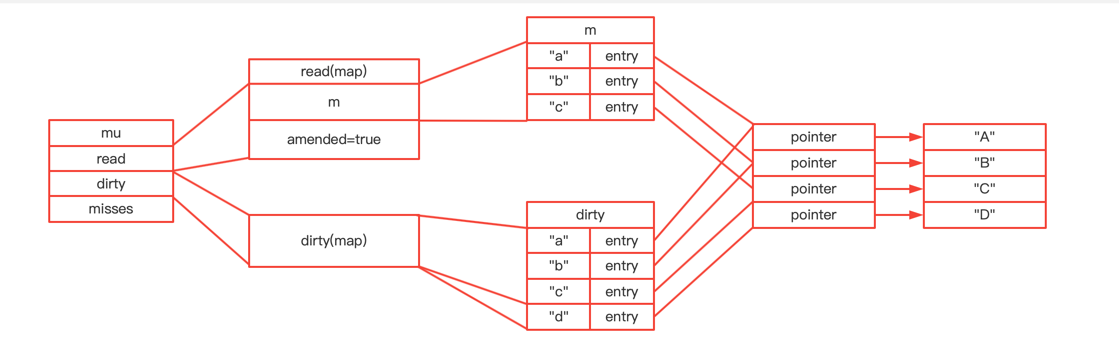
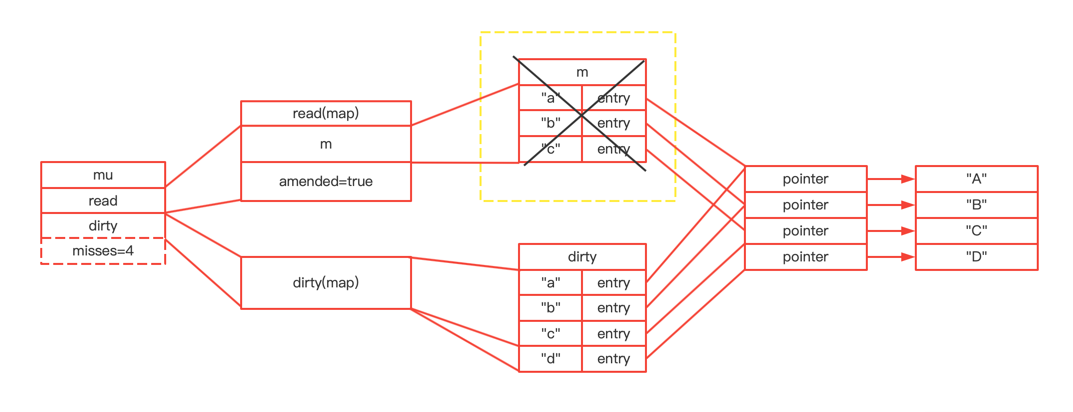
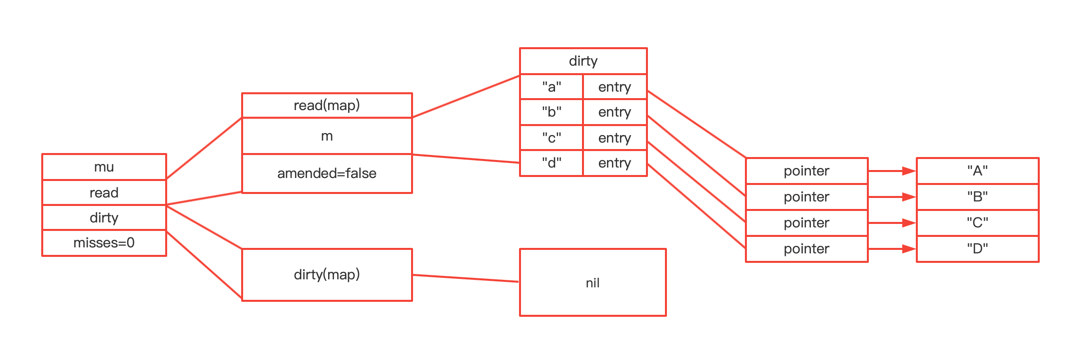
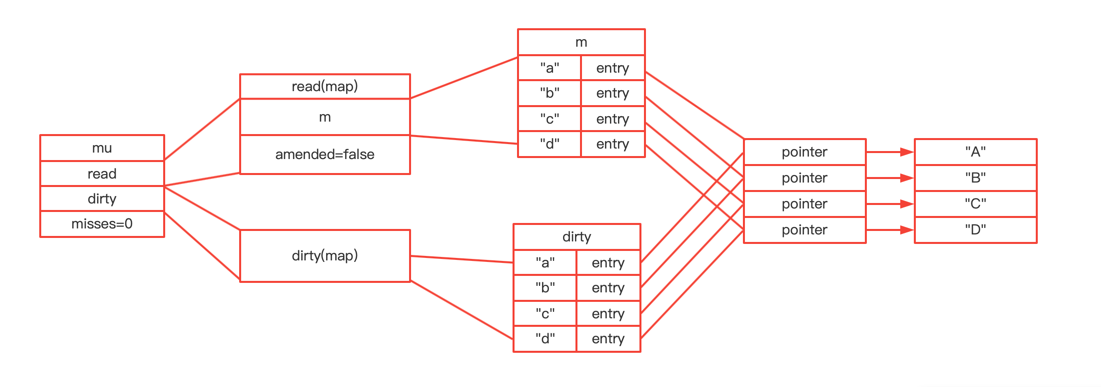
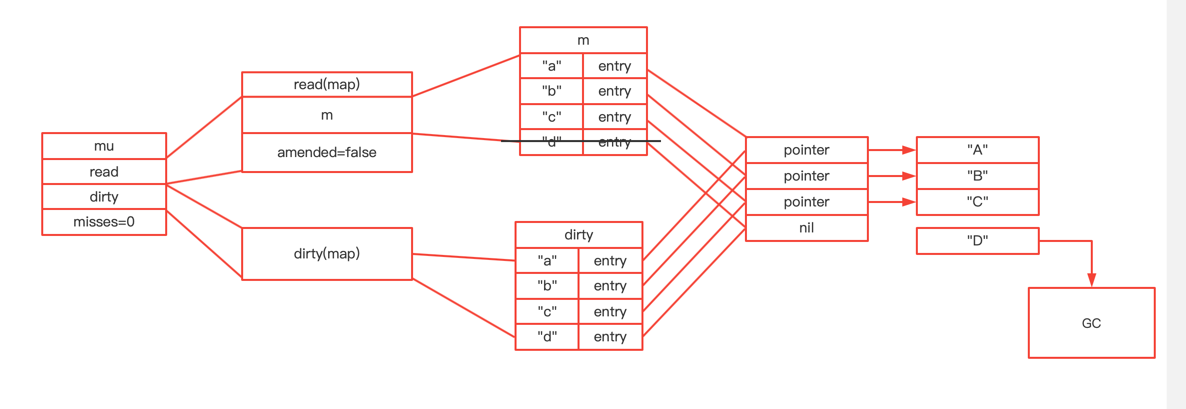
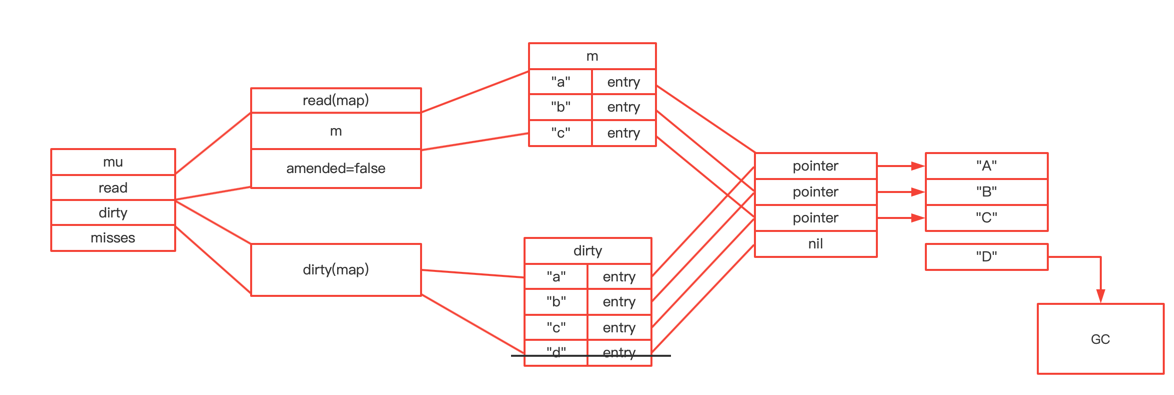
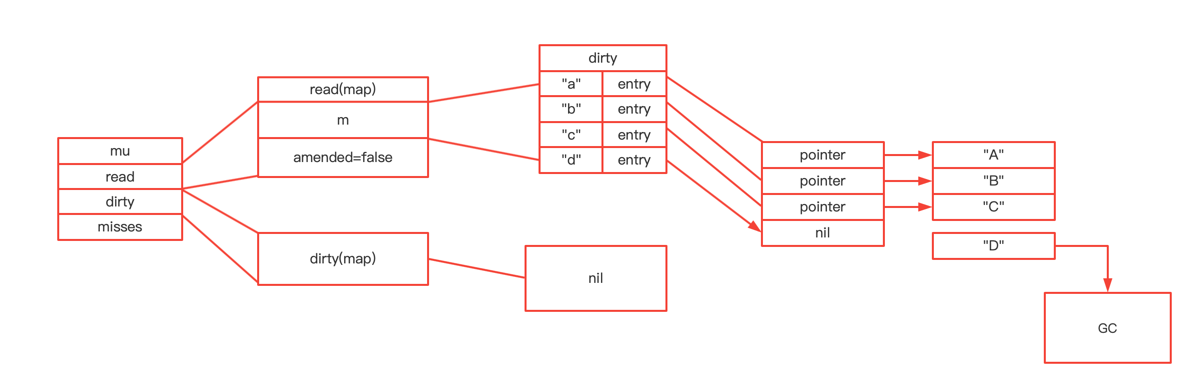
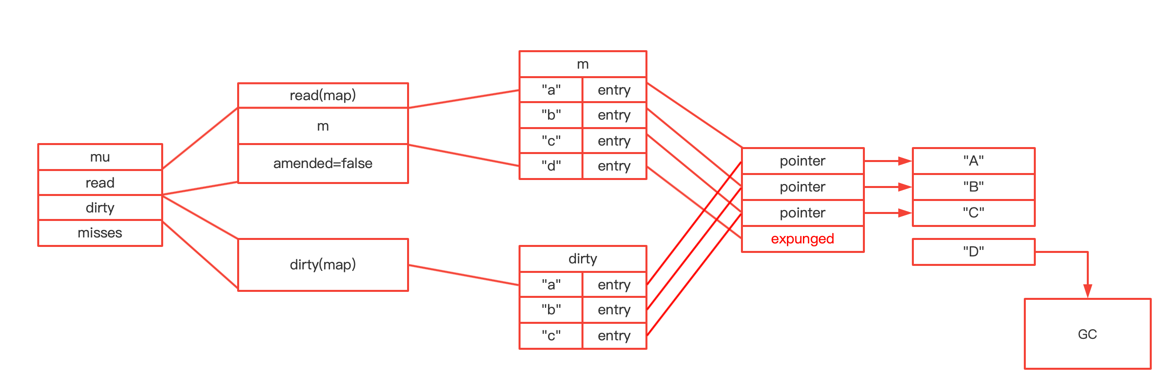
type ServeMux struct { mu sync.RWMutex m map[string]muxEntry es []muxEntry // slice of entries sorted from longest to shortest. hosts bool// whether any patterns contain hostnames }
mux.m[pattern] = e if pattern[len(pattern)-1] == '/' { mux.es = appendSorted(mux.es, e) }
appendSorted详细逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14
funcappendSorted(es []muxEntry, e muxEntry) []muxEntry { n := len(es) i := sort.Search(n, func(i int)bool { returnlen(es[i].pattern) < len(e.pattern) }) if i == n { returnappend(es, e) } // we now know that i points at where we want to insert es = append(es, muxEntry{}) // try to grow the slice in place, any entry works. copy(es[i+1:], es[i:]) // Move shorter entries down es[i] = e return es }
在es中,api前缀的加入是根据parttern的len递减顺序来进行存储的
1 2 3 4 5 6 7 8 9 10 11 12
http.HandleFunc("/api/hello/", func(w http.ResponseWriter, r *http.Request) { w.Write([]byte("Hello World")) }) http.HandleFunc("/api/hello1/", func(w http.ResponseWriter, r *http.Request) { w.Write([]byte("Hello World")) }) http.HandleFunc("/api/hello12/", func(w http.ResponseWriter, r *http.Request) { w.Write([]byte("Hello World")) }) http.HandleFunc("/api/hello3/", func(w http.ResponseWriter, r *http.Request) { w.Write([]byte("Hello World")) })
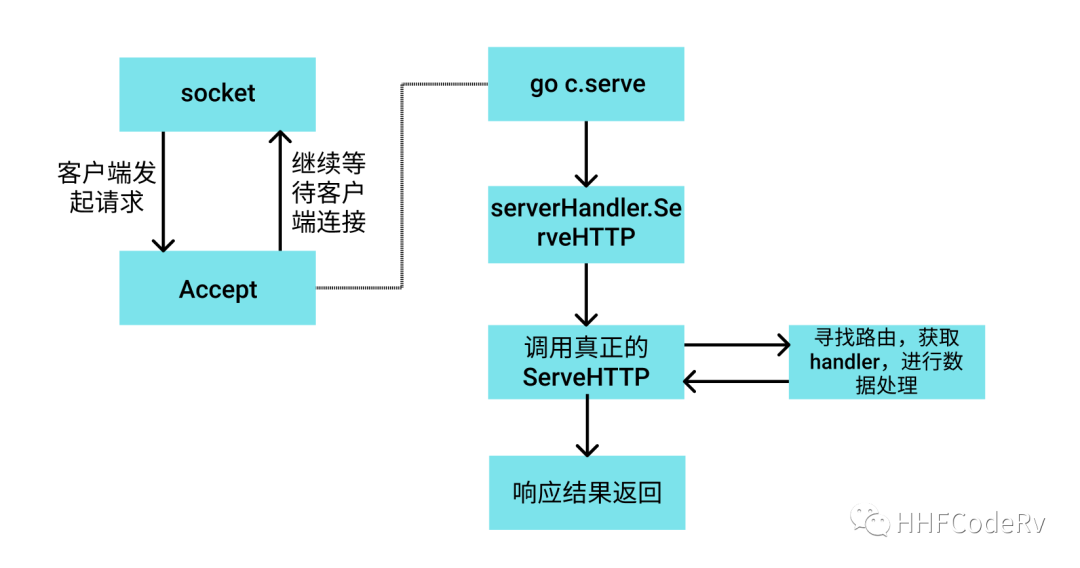
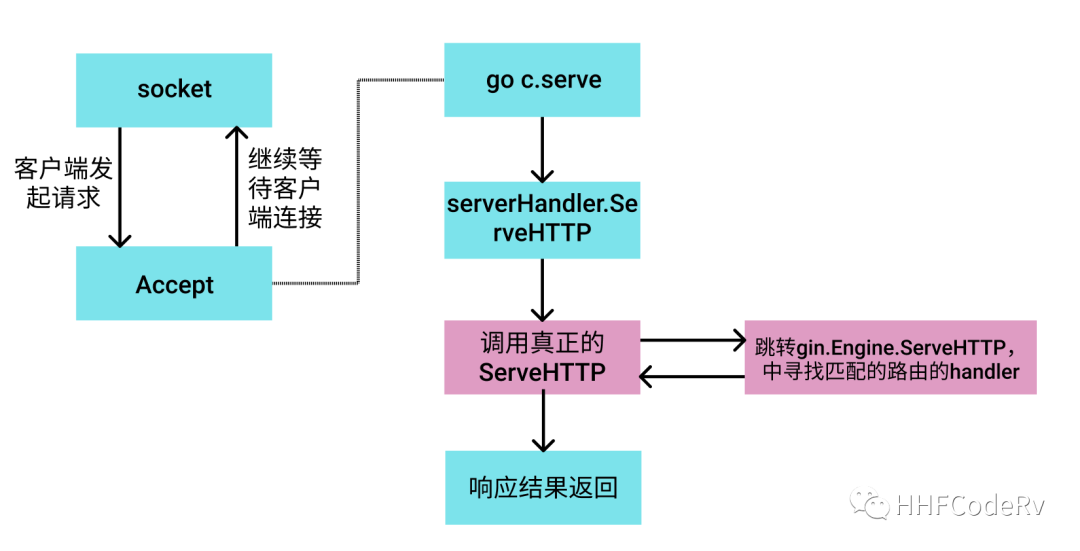
if engine.isUnsafeTrustedProxies() { debugPrint("[WARNING] You trusted all proxies, this is NOT safe. We recommend you to set a value.\n" + "Please check https://pkg.go.dev/github.com/gin-gonic/gin#readme-don-t-trust-all-proxies for details.") }
address := resolveAddress(addr) debugPrint("Listening and serving HTTP on %s\n", address) err = http.ListenAndServe(address, engine.Handler()) return }
// Increments priority of the given child and reorders if necessary // 增加指定孩子节点的优先级,并更新节点的indices // 这并不会影响路由功能,但是可以加快孩子节点的查找速度 func(n *node) incrementChildPrio(pos int) int { cs := n.children cs[pos].priority++ prio := cs[pos].priority
// Build new index char string // 根据优先级重新构建indices,indices保存着当前节点下的每个孩子节点的首字符 if newPos != pos { n.indices = n.indices[:newPos] + // Unchanged prefix, might be empty n.indices[pos:pos+1] + // The index char we move n.indices[newPos:pos] + n.indices[pos+1:] // Rest without char at 'pos' }
return newPos }
// 获两个字符串的最长公共前缀 funclongestCommonPrefix(a, b string)int { i := 0 max := min(len(a), len(b)) for i < max && a[i] == b[i] { i++ } return i }
// addRoute adds a node with the given handle to the path. // Not concurrency-safe! func(n *node) addRoute(path string, handlers HandlersChain) { fullPath := path n.priority++
walk: for { // Find the longest common prefix. // This also implies that the common prefix contains no ':' or '*' // since the existing key can't contain those chars. // 获取最长公共前缀 path代表新加路由节点的path,n.path代表当前node的path i := longestCommonPrefix(path, n.path)
// Make new node a child of this node // 例如n.path=/a path=/abc 新加进来的path比当前n.path长,则进入if语句 // 在当前节点创建一个新的子节点 if i < len(path) { path = path[i:] // 如果n节点的孩子节点有通配符进入if,这里的逻辑会有点绕 if n.wildChild { parentFullPathIndex += len(n.path) //注意,此时n已经指向它的第一个孩子节点 n = n.children[0] n.priority++
// Check if the wildcard matches // 注意,此时的path已经取成了公共前缀后的部分 // 例如原来的路径是/usr/:name,假设当前n节点的父节点为nfather // 而n在前面已经取成了nfather孩子节点 // 目前情况是nfather.path=/usr,由于其子节点是通配符节点 // 故nfather.wildChild=true,n.path=/:name // 假设新加进来的节点path=/:nameserver // 则符合这里的if条件,跳转到walk,以n为父节点继续匹配 iflen(path) >= len(n.path) && n.path == path[:len(n.path)] && // Adding a child to a catchAll is not possible // 不可能在全匹配节点(例如*name)后继续加子节点 n.nType != catchAll && // Check for longer wildcard, e.g. :name and :names (len(n.path) >= len(path) || path[len(n.path)] == '/') { continue walk }
pathSeg := path if n.nType != catchAll { pathSeg = strings.SplitN(path, "/", 2)[0] } prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path panic("'" + pathSeg + "' in new path '" + fullPath + "' conflicts with existing wildcard '" + n.path + "' in existing prefix '" + prefix + "'") } // 注意,此时的path已经取成了公共前缀的后部分 c := path[0]
// slash after param // 如果当前节点是参数节点类型,比如n.path= :name // 且c= / ,且n节点仅有一个孩子节点 if n.nType == param && c == '/' && len(n.children) == 1 { parentFullPathIndex += len(n.path) //当前节点等于子节点 n = n.children[0] //优先级加1 n.priority++ continue walk }
// Check if a child with the next path byte exists // 循环查找,n.indices记录着所有孩子节点的第一个字符 for i, max := 0, len(n.indices); i < max; i++ { //如果找到和当前要插入节点的第一个字符相符,匹配成功 if c == n.indices[i] { parentFullPathIndex += len(n.path) // 对应子节点优先级加1,并对该子节点的indices重新排列 i = n.incrementChildPrio(i) n = n.children[i] continue walk } }
// Otherwise insert it // 如果添加的节点既不是 * 也不是: 这样的通配节点,就执行插入 if c != ':' && c != '*' { // []byte for proper unicode char conversion, see #65 n.indices += bytesconv.BytesToString([]byte{c}) child := &node{ fullPath: fullPath, } n.children = append(n.children, child) n.incrementChildPrio(len(n.indices) - 1) n = child } n.insertChild(path, fullPath, handlers) return }
// Otherwise and handle to current node if n.handlers != nil { panic("handlers are already registered for path '" + fullPath + "'") } n.handlers = handlers n.fullPath = fullPath return } }
// Search for a wildcard segment and check the name for invalid characters. // Returns -1 as index, if no wildcard was found. // wildcard-通配符字符串(例如:name,wildcard就为name) i-通配符在path的索引 valid-是否有合法的通配符 funcfindWildcard(path string) (wildcard string, i int, valid bool) { // Find start for start, c := range []byte(path) { // A wildcard starts with ':' (param) or '*' (catch-all) if c != ':' && c != '*' { continue }
// Find end and check for invalid characters valid = true for end, c := range []byte(path[start+1:]) { switch c { case'/': return path[start : start+1+end], start, valid case':', '*': //一个通配符后还有一个通配符,valid置为false valid = false } } return path[start:], start, valid } return"", -1, false } //插入子节点 func(n *node) insertChild(path string, fullPath string, handlers HandlersChain) { for { // Find prefix until first wildcard wildcard, i, valid := findWildcard(path) if i < 0 { // No wildcard found break }
// The wildcard name must not contain ':' and '*' if !valid { panic("only one wildcard per path segment is allowed, has: '" + wildcard + "' in path '" + fullPath + "'") }
// check if the wildcard has a name iflen(wildcard) < 2 { panic("wildcards must be named with a non-empty name in path '" + fullPath + "'") }
// Check if this node has existing children which would be // unreachable if we insert the wildcard here // 检查此节点是否有现有子节点,如果有子节点,我们在插入通配符,将没办法再访问这些子节点 iflen(n.children) > 0 { panic("wildcard segment '" + wildcard + "' conflicts with existing children in path '" + fullPath + "'") }
if wildcard[0] == ':' { // param if i > 0 { // Insert prefix before the current wildcard // 当前节点n保存通配符的前面部分 n.path = path[:i] path = path[i:] } //wildChild设为true表示子节点有通配符 n.wildChild = true child := &node{ nType: param, path: wildcard, fullPath: fullPath, } n.children = []*node{child} n = child n.priority++
// if the path doesn't end with the wildcard, then there // will be another non-wildcard subpath starting with '/' // 如果通配符后面还有字符,则一定以/为开头 // 例如/:name/age 通配符后还有/age // 这里的英文注释说“将会有另一个以'/'开头的非通配符子路径” // 这不代表不能处理/:name/*hobby这种,上面已经展示了会将通配符的前面部分 // 设为父节点,也就是说通配符节点的父节点一定是一个非通配符节点,英文的注释应该这么理解的 iflen(wildcard) < len(path) { path = path[len(wildcard):]
// Otherwise we're done. Insert the handle in the new leaf n.handlers = handlers return }
// catchAll // 通配符不是:那么就是*,因为*是全匹配的通配符,那么这种情况是不允许的/*name/pwd if i+len(wildcard) != len(path) { panic("catch-all routes are only allowed at the end of the path in path '" + fullPath + "'") } // 如果当前节点的最后一个字符是/,则与全匹配通配符*冲突 iflen(n.path) > 0 && n.path[len(n.path)-1] == '/' { panic("catch-all conflicts with existing handle for the path segment root in path '" + fullPath + "'") }
// currently fixed width 1 for '/' i-- if path[i] != '/' { panic("no / before catch-all in path '" + fullPath + "'") }
n.path = path[:i]
// First node: catchAll node with empty path // *可以匹配0个或多个字符,第一个节点保存为空,也就是*匹配0个字符的情况 child := &node{ wildChild: true, nType: catchAll, fullPath: fullPath, }
n.children = []*node{child} n.indices = string('/') n = child n.priority++
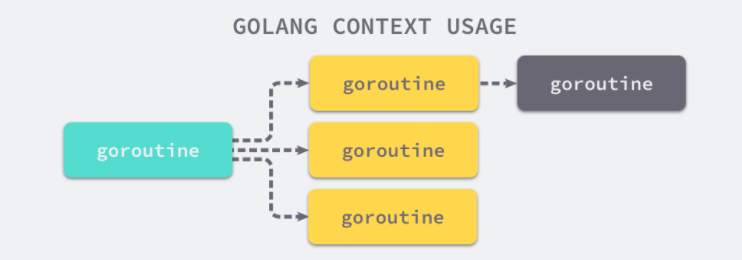
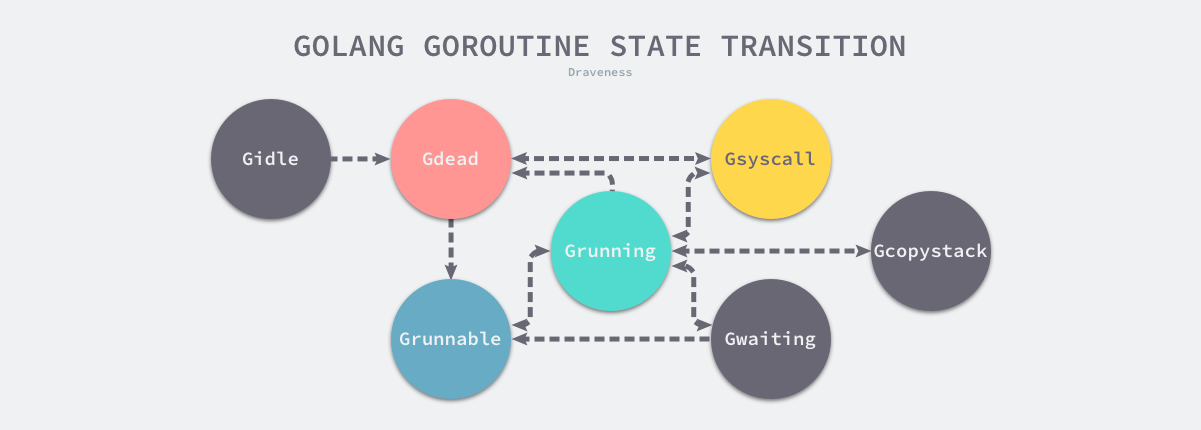
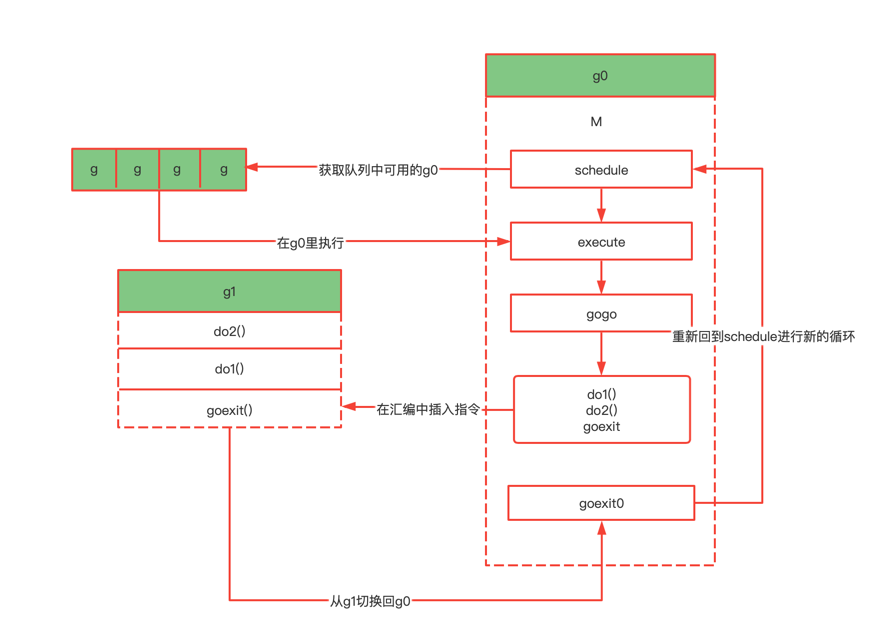
G(Goroutine):G 就是我们所说的 Go 语言中的协程 Goroutine 的缩写,相当于操作系统中的进程控制块。其中存着 goroutine 的运行时栈信息,CPU 的一些寄存器的值以及执行的函数指令等。
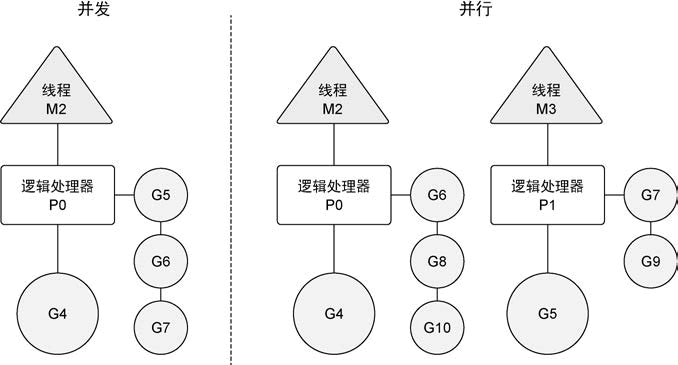
M(Machine):代表一个操作系统的主线程,对内核级线程的封装,数量对应真实的 CPU 数。一个 M 直接关联一个 os 内核线程,用于执行 G。M 会优先从关联的 P 的本地队列中直接获取待执行的 G。M 保存了 M 自身使用的栈信息、当前正在 M上执行的 G 信息、与之绑定的 P 信息。
P(Processor):Processor 代表了 M 所需的上下文环境,代表 M 运行 G 所需要的资源。是处理用户级代码逻辑的处理器,可以将其看作一个局部调度器使 go 代码在一个线程上跑。当 P 有任务时,就需要创建或者唤醒一个系统线程来执行它队列里的任务,所以 P 和 M 是相互绑定的。总的来说,P 可以根据实际情况开启协程去工作,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
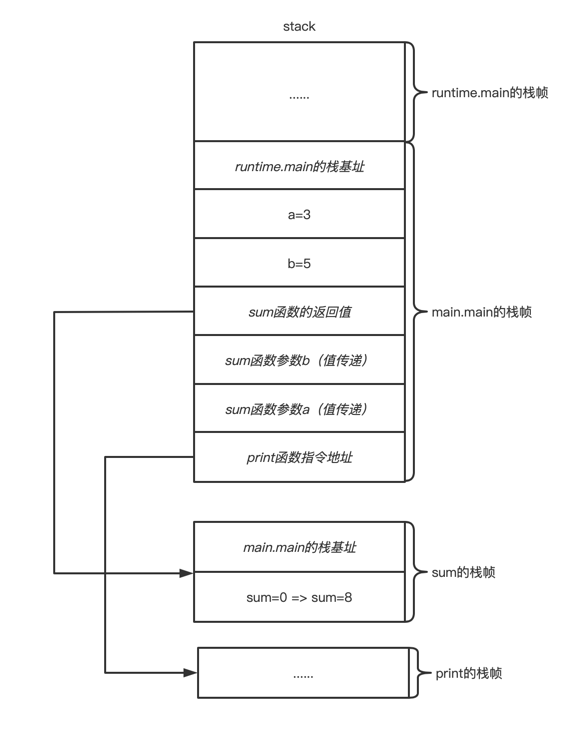
funcsum(a, b int) { sum := 0 sum = a+b return sum }
funcmain() { a:=3 b:=5 print(sum(a, b)) }
参数传递
Go使用参数拷贝(深拷贝)
传递结构体会拷贝结构体全部内容
传递结构体指针,会拷贝结构体指针
协程栈作用总结
协程栈记录了协程的执行现场
协程栈还记录局部变量,函数参数和返回值
Go的函数参数是值传递
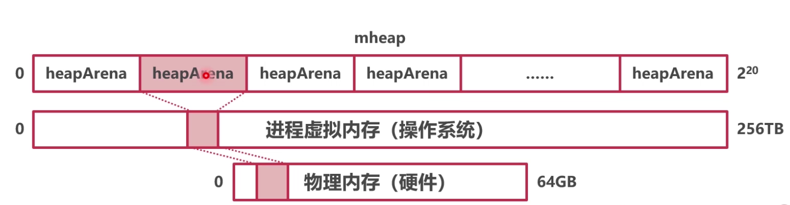
协程栈不够大怎么办?
引起协程栈不够大的主要原因:
本地变量太多
栈帧太多
本地变量太多
当协程栈空间不够大会通过变量从栈逃逸到堆上来得到缓解,因而产生逃逸问题
指针逃逸
函数返回了对象的指针
1 2 3 4 5 6 7 8 9
funcpoint() *int { a := 0 return &a }
funcmain() { i := point() fmt.Println(i) }
go build -gcflags=-m escape.go
1 2 3 4 5 6 7
# command-line-arguments ./escape.go:5:6: can inline point ./escape.go:11:12: inlining call to point ./escape.go:12:13: inlining call to fmt.Println ./escape.go:6:2: moved to heap: a ./escape.go:11:12: moved to heap: a ./escape.go:12:13: ... argument does not escape
空接口逃逸
如果函数的参数是interface,函数的实参很可能会逃逸
1 2 3 4 5 6 7 8
funcintf() { b := 0 fmt.Println(b) }
funcmain() { intf() }
1 2 3 4 5 6
go build -gcflags=-m escape.go # command-line-arguments ./escape.go:7:13: inlining call to fmt.Println ./escape.go:10:6: can inline main ./escape.go:7:13: ... argument does not escape ./escape.go:7:13: b escapes to heap
type p struct { id int32 status uint32// one of pidle/prunning/... link puintptr schedtick uint32// incremented on every scheduler call syscalltick uint32// incremented on every system call sysmontick sysmontick // last tick observed by sysmon m muintptr // back-link to associated m (nil if idle) mcache *mcache ... }
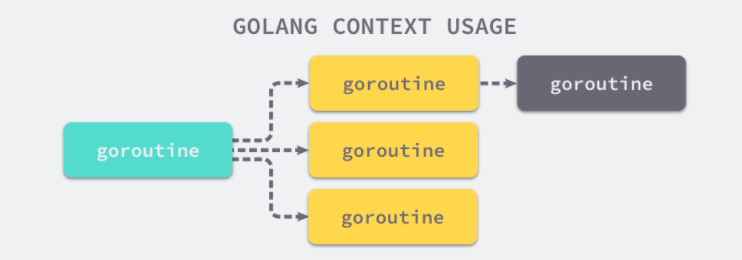
context是 Go 语言在 1.7 版本中引入标准库的接口。context主要用于父子任务之间的同步取消信号,本质上是一种协程调度的方式。另外在使用context时有两点值得注意:上游任务仅仅使用context通知下游任务不再需要,但不会直接干涉和中断下游任务的执行,由下游任务自行决定后续的处理操作,也就是说context的取消操作是无侵入的;context是线程安全的,因为context本身是不可变的(immutable),因此可以放心地在多个协程中传递使用。
// Go 1.18的扩容实现代码如下,et是切片里的元素类型,old是原切片,cap等于原切片的长度+append新增的元素个数。 funcgrowslice(et *_type, old slice, capint) slice { // ... newcap := old.cap doublecap := newcap + newcap ifcap > doublecap { newcap = cap } else { const threshold = 256 if old.cap < threshold { newcap = doublecap } else { // Check 0 < newcap to detect overflow // and prevent an infinite loop. for0 < newcap && newcap < cap { // Transition from growing 2x for small slices // to growing 1.25x for large slices. This formula // gives a smooth-ish transition between the two. newcap += (newcap + 3*threshold) / 4 } // Set newcap to the requested cap when // the newcap calculation overflowed. if newcap <= 0 { newcap = cap } } }
type Mutex struct { state int32 sema uint32 } type RWMutex struct { w Mutex // held if there are pending writers writerSem uint32// semaphore for writers to wait for completing readers readerSem uint32// semaphore for readers to wait for completing writers readerCount int32// number of pending readers readerWait int32// number of departing readers }
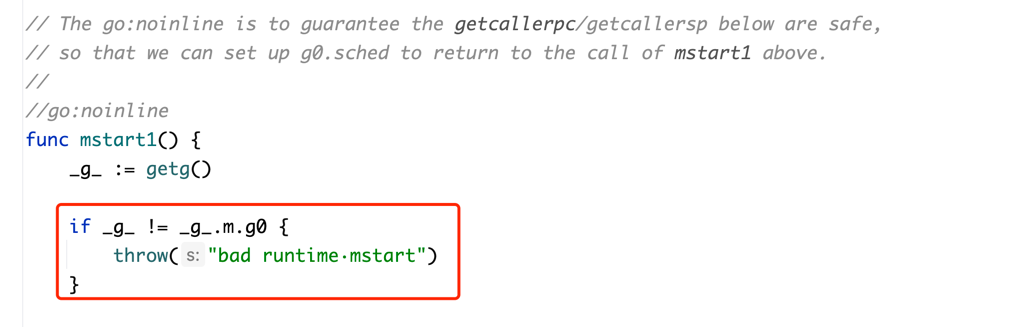
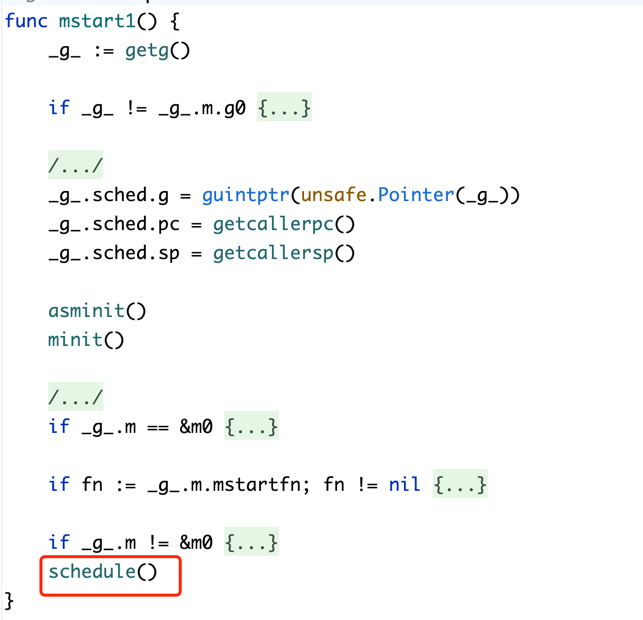
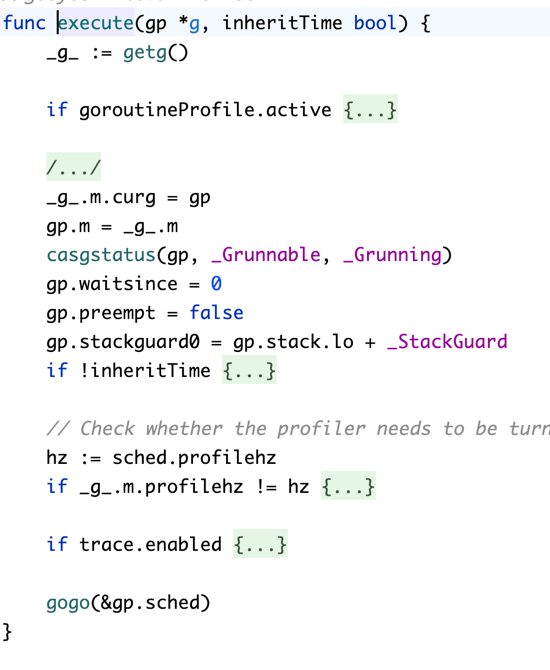
funcsemacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) { gp := getg() if gp != gp.m.curg { throw("semacquire not on the G stack") }
// Easy case. if cansemacquire(addr) { return }
// Harder case: // increment waiter count // try cansemacquire one more time, return if succeeded // enqueue itself as a waiter // sleep // (waiter descriptor is dequeued by signaler) s := acquireSudog() root := semtable.rootFor(addr) t0 := int64(0) s.releasetime = 0 s.acquiretime = 0 s.ticket = 0 if profile&semaBlockProfile != 0 && blockprofilerate > 0 { t0 = cputicks() s.releasetime = -1 } if profile&semaMutexProfile != 0 && mutexprofilerate > 0 { if t0 == 0 { t0 = cputicks() } s.acquiretime = t0 } for { lockWithRank(&root.lock, lockRankRoot) // Add ourselves to nwait to disable "easy case" in semrelease. atomic.Xadd(&root.nwait, 1) // Check cansemacquire to avoid missed wakeup. if cansemacquire(addr) { atomic.Xadd(&root.nwait, -1) unlock(&root.lock) break } // Any semrelease after the cansemacquire knows we're waiting // (we set nwait above), so go to sleep. root.queue(addr, s, lifo) goparkunlock(&root.lock, waitReasonSemacquire, traceEvGoBlockSync, 4+skipframes) if s.ticket != 0 || cansemacquire(addr) { break } } if s.releasetime > 0 { blockevent(s.releasetime-t0, 3+skipframes) } releaseSudog(s) }
分步骤分析
1 2 3 4
gp := getg() if gp != gp.m.curg { throw("semacquire not on the G stack") }
这一段主要是用来获取sema的当前协程栈,如果拿不到的话会抛出异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14
if cansemacquire(addr) { return } funccansemacquire(addr *uint32)bool { for { v := atomic.Load(addr) if v == 0 { returnfalse } if atomic.Cas(addr, v, v-1) { returntrue } } }
// Easy case: no waiters? // This check must happen after the xadd, to avoid a missed wakeup // (see loop in semacquire). if atomic.Load(&root.nwait) == 0 { return }
// Harder case: search for a waiter and wake it. lockWithRank(&root.lock, lockRankRoot) if atomic.Load(&root.nwait) == 0 { // The count is already consumed by another goroutine, // so no need to wake up another goroutine. unlock(&root.lock) return } s, t0 := root.dequeue(addr) if s != nil { atomic.Xadd(&root.nwait, -1) } unlock(&root.lock) if s != nil { // May be slow or even yield, so unlock first acquiretime := s.acquiretime if acquiretime != 0 { mutexevent(t0-acquiretime, 3+skipframes) } if s.ticket != 0 { throw("corrupted semaphore ticket") } if handoff && cansemacquire(addr) { s.ticket = 1 } readyWithTime(s, 5+skipframes) if s.ticket == 1 && getg().m.locks == 0 { // Direct G handoff // readyWithTime has added the waiter G as runnext in the // current P; we now call the scheduler so that we start running // the waiter G immediately. // Note that waiter inherits our time slice: this is desirable // to avoid having a highly contended semaphore hog the P // indefinitely. goyield is like Gosched, but it emits a // "preempted" trace event instead and, more importantly, puts // the current G on the local runq instead of the global one. // We only do this in the starving regime (handoff=true), as in // the non-starving case it is possible for a different waiter // to acquire the semaphore while we are yielding/scheduling, // and this would be wasteful. We wait instead to enter starving // regime, and then we start to do direct handoffs of ticket and // P. // See issue 33747 for discussion. goyield() } } }
funcmakemap(t *maptype, hint int, h *hmap) *hmap { mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size) if overflow || mem > maxAlloc { hint = 0 }
// initialize Hmap if h == nil { h = new(hmap) } h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements. // For hint < 0 overLoadFactor returns false since hint < bucketCnt. B := uint8(0) for overLoadFactor(hint, B) { B++ } h.B = B
// allocate initial hash table // if B == 0, the buckets field is allocated lazily later (in mapassign) // If hint is large zeroing this memory could take a while. if h.B != 0 { var nextOverflow *bmap h.buckets, nextOverflow = makeBucketArray(t, h.B, nil) if nextOverflow != nil { h.extra = new(mapextra) h.extra.nextOverflow = nextOverflow } }
return h }
makemap 函数通过指定hint来通过B计算bucket数量 计算公式
1
hint ≤ 2^B * 6.5
通过B数量指定hmap会创建2^B个桶和一些溢出桶
1 2 3 4 5 6 7 8 9 10 11
if b >= 4 { // Add on the estimated number of overflow buckets // required to insert the median number of elements // used with this value of b. nbuckets += bucketShift(b - 4) sz := t.bucket.size * nbuckets up := roundupsize(sz) if up != sz { nbuckets = up / t.bucket.size } }
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again }
if !h.sameSizeGrow() { // Only calculate y pointers if we're growing bigger. // Otherwise GC can see bad pointers. y := &xy[1] y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize))) y.k = add(unsafe.Pointer(y.b), dataOffset) y.e = add(y.k, bucketCnt*uintptr(t.keysize)) }
//hash&m找到桶编号作为偏移值找到对应的bmap结构体 b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) if c := h.oldbuckets; c != nil { //存在旧桶,说明正在扩容状态中 if !h.sameSizeGrow() { //判断是否翻倍扩容 m >>= 1//翻倍扩容时,新的桶数是旧的2倍,m需要减半才能找到旧桶编号 } oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))) //找到对应的旧桶位置 if !evacuated(oldb) { b = oldb //如果旧桶没有完成数据迁移,那么更新b指向旧桶bmap } } top := tophash(hash) //取hash值高八位,因为bmp.tophash中0-4是标志位,所以hash值小于5的自动加5 bucketloop: //遍历当前bmp和溢出桶 ...