RESTful
目前业界 Server 端 API 接口的设计方式一般是遵循 RESTful 风格的规范
1 | GET /user/{userID} HTTP/1.1 |
这是比较规范的 RESTful API设计,分别代表:
- 获取 userID 的用户信息
- 更新 userID 的用户信息(当然还有其 json body,没有写出来)
- 创建 userID 的用户(当然还有其 json body,没有写出来)
- 删除 userID 的用户
gin 路由设计
前缀树和基数树(radix tree)
前缀树是一个多叉树,广泛应用于字符串搜索,每个树节点存储一个字符,从根节点到任意一个叶子结点串起来就是一个字符串。
radix tree是优化之后的前缀树,对空间进一步压缩,从上往下提取公共前缀,非公共部分存到子节点,这样既节省了空间,同时也提高了查询效率(左边字符串sleep查询需要5步, 右边只需要3步),Gin的路由树就是用radix tree实现的。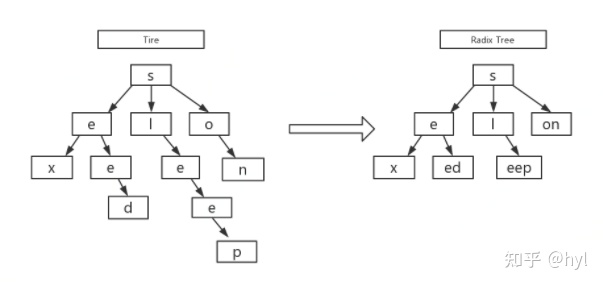
Gin为每一种请求都维护了一个radix tree,不同的请求会被解析并送到对应的radix tree进行处理。
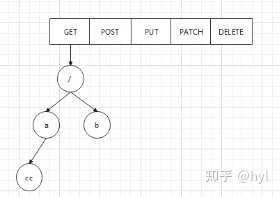
gin的路由树的一些相关结构体介绍
1 | type Engine struct { |
当 gin 注册路由的时候,会根据不同的 Method 分别注册不同的路由树。
如上面的restful请求会注册四颗路由树出来。
1 | func (engine *Engine) addRoute(method, path string, handlers HandlersChain) { |
流程
- 拿到一个
method方法时,去trees slice中遍历 - 如果
trees slice存在这个method, 则这个URL对应的handler直接添加到找到的路由树上 - 如果没有找到,则重新创建一颗新的方法树出来, 然后将 URL对应的
handler添加到这个路由 树上
这里的重点是根节点root调用的addRoute,添加节点的逻辑都在这个函数里面,包括找到插入的位置,一些通配节点的特殊处理等。在这个函数里面会用到一些工具函数,这里一并介绍一下
1 | // Increments priority of the given child and reorders if necessary |
Priority 优先级
为了能快速找到并组合完整的路由,GIN 在添加路由的同时,会在每个节点中添加 Priority 这个属性。在查找时根据 Priority 进行排序,常用节点(通过次数理论最多的节点) 在最前,并且同一层级里面 Priority 值越大,越优先进行匹配。
1 | // Search for a wildcard segment and check the name for invalid characters. |