回溯模版总结
适用于结果路径里元素不可重复使用
1 | 创建空slice |
适用于结果路径里元素可重复使用,排列顺序不能重复
1 | 创建空slice |
适用于结果路径里元素不可重复使用
1 | 创建空slice |
适用于结果路径里元素可重复使用,排列顺序不能重复
1 | 创建空slice |
以力扣https://leetcode.cn/problems/generate-parentheses/submissions/393569541/算法为例:
题目要求:输入一个数字n:数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且有效的括号组合
根据题目要求:可分析得到要生成n对括号,并且括号是有效括号,由于题目要求列出所有组合可能,所以我们要将括号拆分成(和),这样我们一共需要生成2n个这样的括号 先发挥我们的大脑想象😇,列举出这2n个括号的所有排列组合
已n=2为例:
1 | )))) |
可枚举出16种可能,但是这些结果集并不是我们都需要的,因此我们需要针对有效括号的特性做出一些筛减;分析至此,会很轻易发现,这是不是和回溯的思想很类似呢?回溯的核心思想是:在for循环里面进行递归,枚举出所有可能,在递归调用之前「做选择」,在递归调用之后「撤销选择」;而做选择就是对穷举的排列组合进行筛减,判断出不合法的选择,然后过滤掉,这种过程通常被叫做剪枝。撤销选择即探索过程中发现并不优或达不到目标,就退回一步重新选择
枚举所有可能的代码很好实现:
1 | func GenerateParenthesis(n int) []string { |
递归为什么可实现枚举?
分析过程:
如果输入为2,要生成2n个括号可得出n=4,因为函数是在栈中调用的,并且递归嵌套调用
所以当:
n=1时:backtrack(0, back + ")")和backtrack(0, back + "(")都被压入到栈中
n=2时:backtrack(1, back + ")")和backtrack(1, back + "(")都被压入到栈中
n=3时:backtrack(2, back + ")")和backtrack(3, back + "(")都被压入到栈中
n=4时:backtrack(3, back + ")")和backtrack(3, back + "(")都被压入到栈中
不难分析,当:
n=0时为终止条件,直接输出
n=1时n = n-1 函数调用为backtrack(0, back + ")"),对应了两种结果集:)和(都被压入栈中,会输出)和(两种可能;函数被压入栈中2次
n=2时n = n-1 函数调用为backtrack(1, back + ")"),对应了刚才n=1时两种输出结果集;backtrack(1, back + "(")也对应了n=1的两种输出结果集,想加后一共会输出))、((、()、)(四种可能;函数被压入栈中4次
n=3时n = n-1 函数调用为backtrack(2, back + ")"),对应了刚才n=2时的两种输出结果集;backtrack(2, back + "(")也对应了n=2的两种输出结果集,想加后一共会输出))) ))( )() )(( ()) ()( (() (((八种可能;函数被压入栈中8次
n=4时n = n-1 函数调用为backtrack(3, back + ")"),对应了刚才n=3时的两种输出结果集;backtrack(3, back + "(")也对应了n=3的两种输出结果集,想加后一共会输出…十六种可能;函数被压入栈中16次
n=x时n = x-1 函数调用为backtrack(x-1, back + ")")和backtrack(x-1, back + "(")对应了2 * (backtrack(x-1))种可能);函数被压入栈中次2 * (backtrack(x-1))次
总结:枚举不同可能是一个不断搜索尝试的过程,由于枚举过程需要保存上一次枚举的结果集,而函数参数值在每次函数调用的过程中会保存下来,利用这一特性我们只要在递归终止条件中,将递归后的结果集保存下来就可以穷举出所有可能。
剪枝就是在穷举的结果集中过滤到不合法的结果集
根据题意可分析到剪枝条件:
左括号数量不能超出n/2
左括号一定要先于右括号出现
右括号数量不能超出n/2
所以我们要在递归调用中增加函数参数,来保存左括号和右括号出现的次数
1 | var backtrack func (int, string, int, int) |
根据刚才的剪枝分析增加判断条件
1 | // 必须先保证左括号先出现,才能出现右括号 |
由于保证了left出现次数不会超过n/2,并且总出现次数限制为n(n=0时函数会退出),所以右括号数量不能超出n/2的判断代码不用实现
由于函数在递归调用过程中,n由于减1会发生变化,我们需要在全局变量中声明m并保存n的初始值
1 | var backtrack func (int, string, int, int) |
1 | func generateParenthesis(n int) []string { |
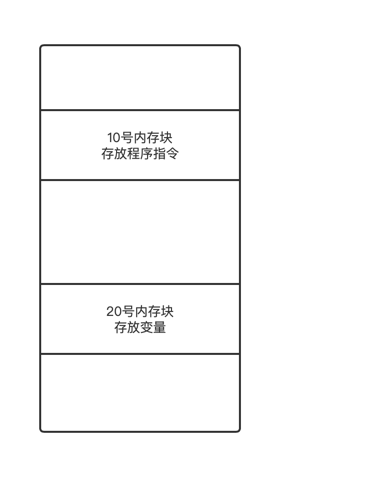
1 | int i = 0; |
这个程序会很频繁的访问下图中的10号和20号内存块
时间局部性:如果执行了程序中的某条指令,那么不久后这条指令很有可能再次执行:如果某个数据被访问过,不久之后该数据很可能再次被访问。(因为程序中存在大量的循环)
空间局部性: 一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的)
在地址转化过程中,每次要访问一个逻辑地址,都需要查询内存中的页表。由于局部性原理,可能连续很多次查到的都是同一个页表项。既然如此,能否利用这个特性减少访问页表的次数呢?
快表,又称联想寄存器(TLB) 是一种访问速度比内存快很多的高速缓冲存储器,用来存放当前访问的若干页表项,以加速地址变换的过程。与此对应,内存中的页表常称为慢表。
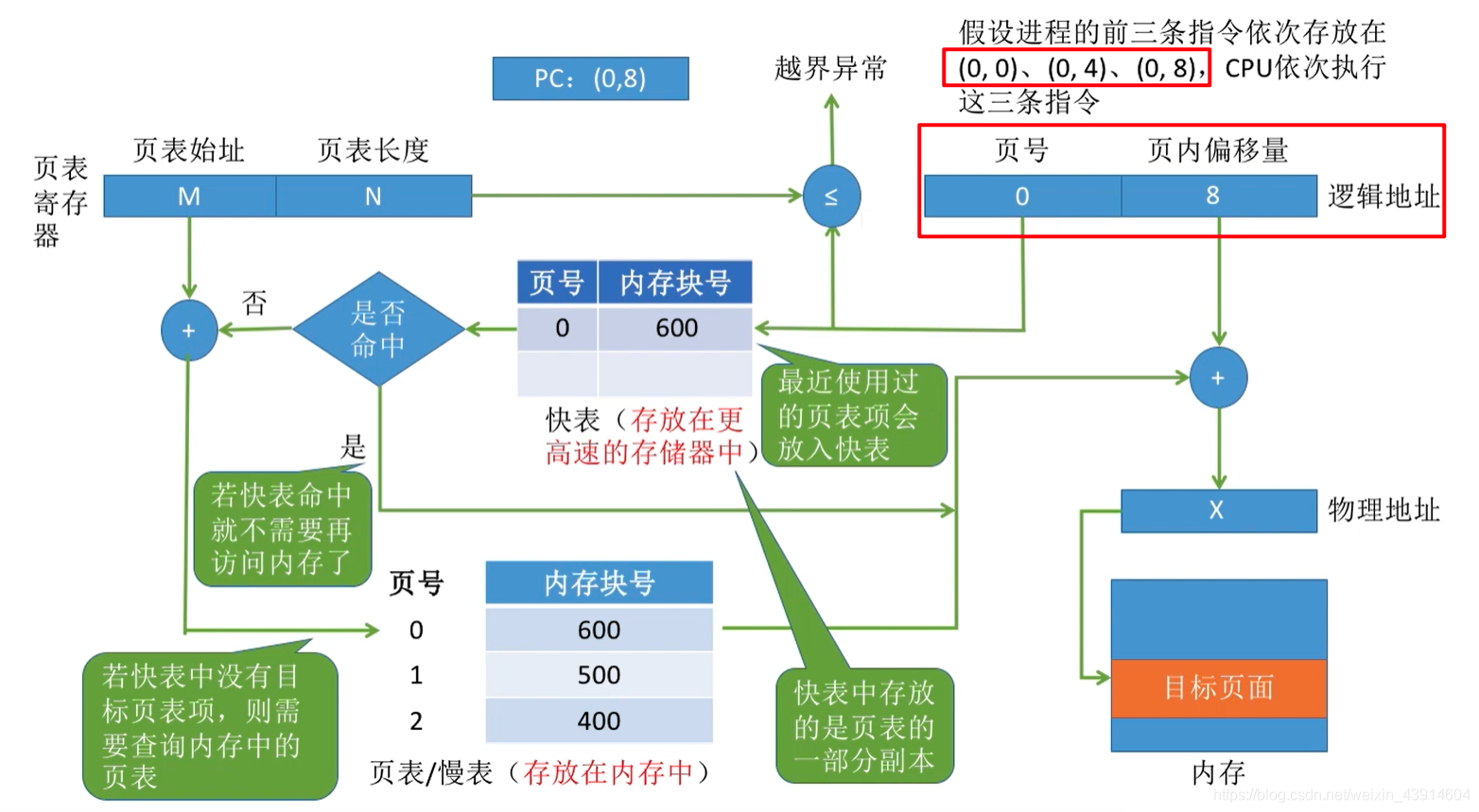
引入快表后,地址变换的过程的文字描述:
由于查询快表的速度比查询页表的速度快很多,因此只要快表命中,就可以节省很多时间。 因为局部性原理, 一般来说快表的命中率可以达到90%以上。 查询内存中的慢表(页表) 经过计算查询内存中物理地址的内存单元
例:某系统使用基本分页存储管理,并采用了具有快表的地址交换机构。访问一次快表耗时 1us,访 问一次内存耗时 100us。若快表的命中率为 90%,那么访问一个逻辑地址的平均耗时是多少?(1+100)* 0.9+ (1+100+100)0.1=111us 有的系统文持快表和投表同时查找,如果是这样,平均耗时应该是 (1+100) 0.9 + (100+100) *0.1 = 110.9 us 若未采用快表机制,则访问一个逻辑地址需要 100+100=200us 显然,引入快表机制后,访问一个逻辑地址的速度快多了。
某计算机系统按字节寻址,支持32位的逻辑地址,采用分页存储管理,页面大小为4KB,页表项长度为 4B。 4KB= 2^12B,因此页内地址要用12位表示,剩余20位表示页号。 因此,该系统中用户进程最多有2^20页。相应的,一个进程的页表中,最多会有2^20 =1M=1,048,576个页表项,所以一个页表最大需要 2^20*4B=2^22B,共需要 2^22/2^12=2^10 个页框存储该页表。 根据局部性原理可知,很多时候,进程在一段时间内只需要访问某几个页面就可以正常运行了。因此没有必要让整个页表都常驻内存。
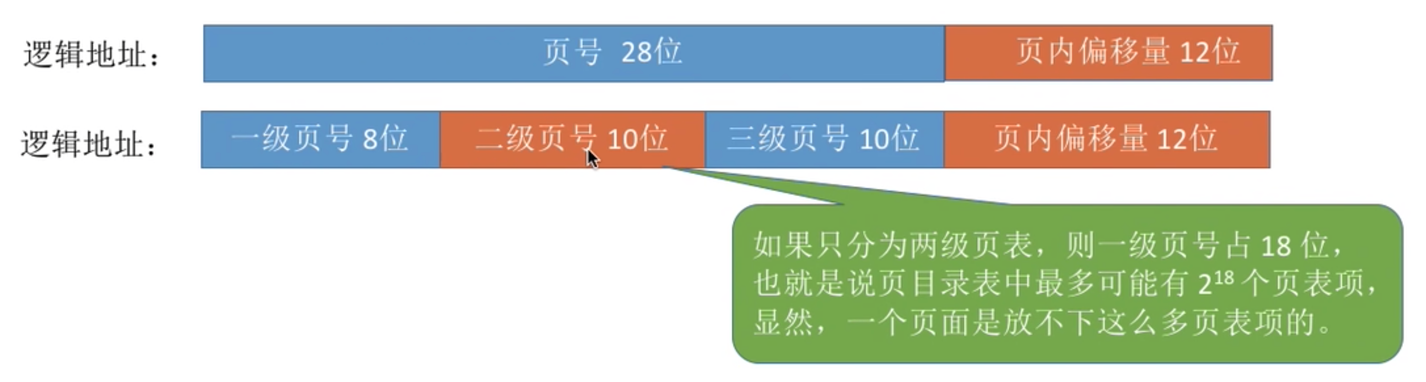
上面提到了这两个问题,针对问题一,可以引入二级页表的概念来解决。
在32位逻辑地址空间,页表项大小为4kb,页面大小4kb,页内地址占12位
| 31 … 12 | 11 … 0 |
|---|---|
| 页号 | 页面偏移量 |
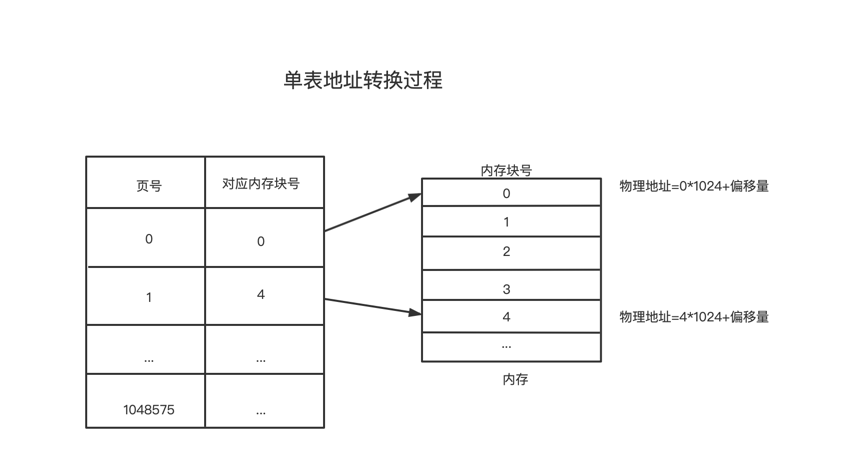
将页表进行拆分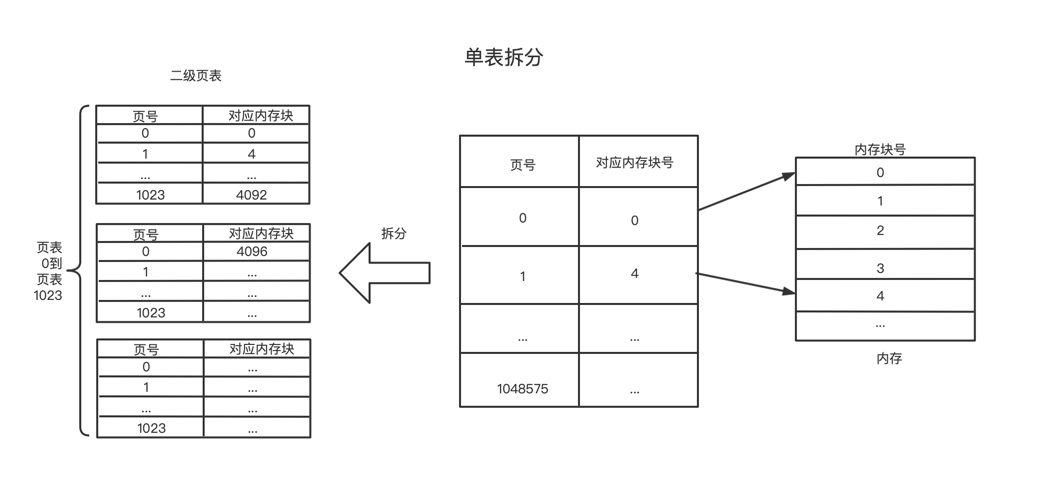
拆分后页表查找过程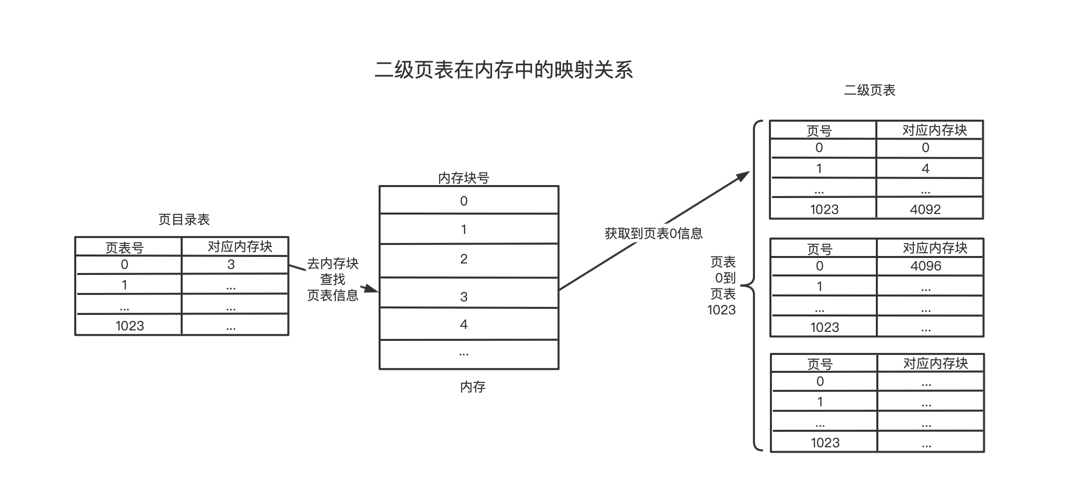
二级页表的地转换过程:
例如:17407的32位二进制可表示为(0000000000,0000000100,001111111111)
0000000000到页目录表查找页表内存块3,然后访问内存块3得到页表信息0000000100对应二级页表的下标为4,所以在页表0中下标4页号的内存块号为16;1024个页表,可得知,每个页表大小为4b,所以16内存号的起始地址为16*1024=16384001111111111计算得知为1023,所以最终物理地址为16384+1023=17407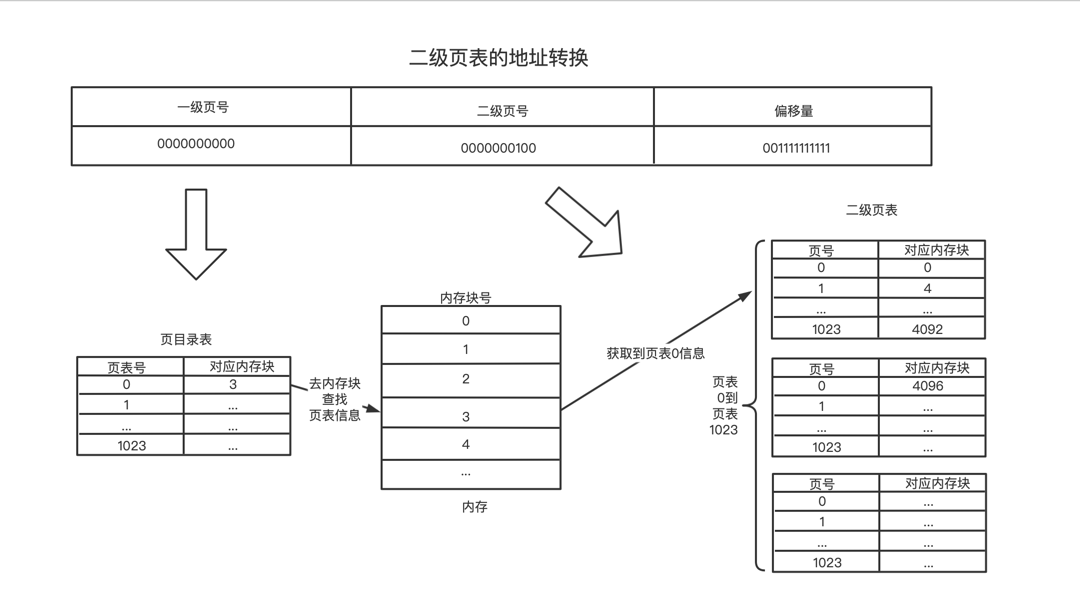
两级页表的访存次数分析(假设没有快表机制)
上面的部分我们解决了问题一,接下来是问题二,这里简单叙述一下,详细内容在页面置换算法文章中会提到
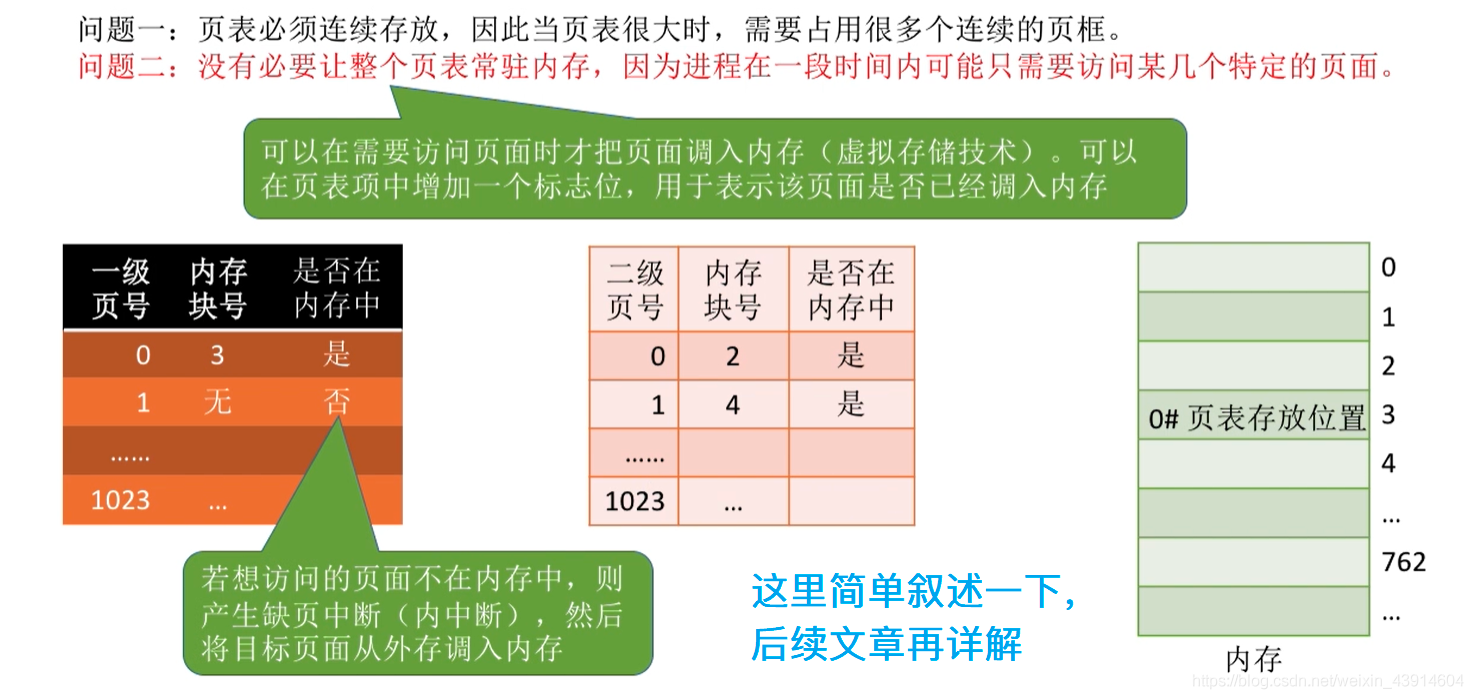
若采用多级页表机制,则各级页表的大小不能超过一个页面
例:某系统按字节编址,采用 40 位逻银地址,页面大小为 4KB,页表项大小为 4B,假设采用纯页式存储,则要采用()级页表,页内偏移量为()位?
页面大小=4KB=2^12B,按字节编址,因此页内偏移量为12位 页号=40-12=28份 页面大小=2^12B,页表项大小=4B,则每个页面可存放 2^12/4=2^10个页表项 因此各级页表最多包含2^10个页表项, 需要10位二进制位才能映射到2^10个页表项,因此每一级的页表对应页号应为10位。总共28位的页号至少要分为三级
参考文献:王道计算机考研-操作系统
考虑多道程序设计连续内存分配两种管理方式
非连续内存管理方式分为下图几种
假设进程A大小为23MB,但是每个分区大小只有10MB,如果进程只能占用一个分区,那显然放不下。
解决思路:如果允许进程占用多个分区,那么可以把进程拆分成10MB+10MB+3MB三个部分,再把这三个部分分别放到三个分区中(这些分区不要求连续)
进程A的最后一个部分是3MB,放入分区后会产生 7MB 的内部碎片。
如果每个分区大小为 2MB,那么进程A可以拆分成 11* 2MB + 1MB 共12个部分,只有最后一部分 1MB占不满分区,会产生 1MB 的内部碎片。
显然,如果把分区大小设置的更小一些,内部碎片会更小,内存利用率会更高。
将内存空间分为一个个大小相等的分区(比如:每个分区4KB),每个分区就是一个“页框”,或称“页帧” “内存块” “物理块” 。每个页框有一个编号,即“页框号” (或 者“内存块号” “页帧号” “物理块号〞,页框号从O开 始 将用户进程的地址空问也分为与页框大人相等的一个个区城, 称为“页”或“页面” 。每个页面也有 一个编号,即“页号” 页号也是从0开始。
(注:进程的最后一个页面可能没有一个页框那么大。因此, 页框不能太大,否则可能产生过大的内部碎片)
操作系统以页框为单位为各个进程分配内存空间。进程的每个页面分别放入一个页框中。也就是说,进程的页面与内存的页 框有一对应的关系。 各个页面不必连续存放,也不必按先后顺序来,可以放到不相邻的各个页框中。
假设每页大小50b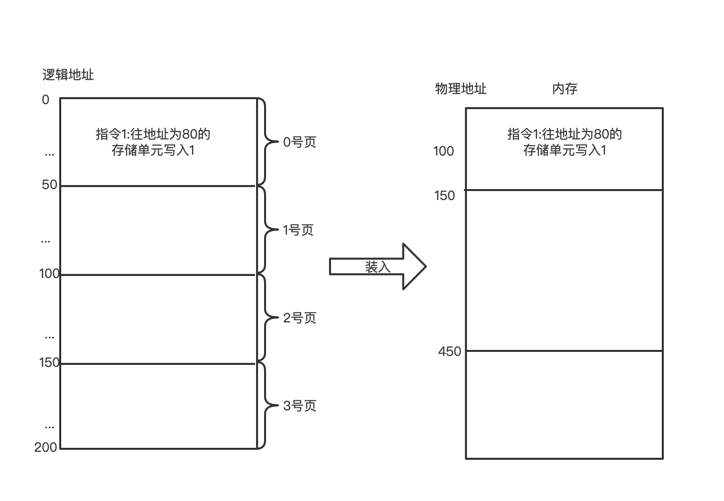
逻辑地址为80的内存单元: 应该在1号页,该页在内存中的起始位置为450,逻辑地址为80的内存单元相对于该页的起始地址而言, “偏移量”应该是30。 实际物理地址450+30=480
页号:80 / 50 = 1
偏移量:80 % 50 = 30
1号页在内存的起始位置为450
为了方便计算页号,偏移量和页面大小一般为2的幂次方
逻辑地址 4097,用二进制表示应该是 00000000000000000001000000000001 若 1号页在内存中的起始地址为x,则逻辑地址4097对应的物理地址应该是x+1000000000001
如何计算: 页号=逻辑地址/ 页面长度(取除法的整数部分)
为了方便计算 页而大小一般 页内偏移量=逻辑地址 % 页面长度(取除法的余数部分)
假设用32个二进制位表示逻辑地址,页面大小为 210B=1024B= 1KB
0号页的逻辑地址空间应该是 0~1023,用二进制表示应该是: 00000000000000000000000000000000 ~ 00000000000000000000001111111111
1号页的逻辑地址空间应该是 1024~2047,用二进制表示恩该是: 00000000000000000000010000000000 ~ 00000000000000000000011111111111
2号页的逻辑地址空间应该是 2048~3021,用二进制表示应该是: 00000000000000000000100000000000 ~ 00000000000000000000101111111111
结论:如果每个页面大小为 2^B,用二进制数表示逻辑地址,则末尾K位即为页内便宜量,其余部分就是页号,因此,如果让每个页面的大小为2的整数幂,计算机就可以很方便地得出一个逻辑地址和页内偏移量。
例如计算1026和2055的页号和页面偏移量
1026的32位二进制表示为00000000000000000000010000000010
如果每个页面大小为2^10,末尾10位为0000000010,可得出页面偏移量为2,其余部分为0000000000000000000001,可得出在1号页
2055的32位二进制表示为00000000000000000000100000000111
如果每个页面大小为2^10,末尾10位为0000000111,可得出页面偏移量为7,其余部分为0000000000000000000010,可得出在2号页
这里引入一个新概念页表
为了能知道进程的每个页面在内存中存放的位置,操作系统要为每个进程建立一张页表。
参考文献:王道计算机考研-操作系统
支持多道程序,在进程进入内存时,动态根据进程大小划分分区
2种数据结构
进程多大,分区就多大,所以没有内部碎片,但是有外部碎片,外部碎片可以用紧凑技术解决
回收内存分区时,有4种情况
总之,相连的空闲分区要合并
| 算法 | 思想 | 分区排列顺序 | 优点 | 缺点 |
|---|---|---|---|---|
| 首次适应 | 从头到尾找到适合的分区 | 空闲分区以地址递增次序排列 | 性能最好,算法开销小回收后不需要对空闲分区重新排序 | |
| 最佳适应 | 优先使用更小的分区,以保留更多的分区 | 空闲分区以容量递增次序排列 | 会有更多的大分区被保留下来,更能满足大进程需求 | 会产生很多小、难以利用的碎片,算法开销大,回收后可能需要对空闲分区队列重新排序 |
| 最坏适应 | 优先使用更大的分区,以防止产生太多太小的不可用的碎片 | 空闲分区以容量递增次序排列 | 可以减少许多难以利用的小碎片 | 大分区容易被用完,不利于大进程,算法开销大 |
| 邻近适应 | 由首次适应演变而来,每次从上次查找结束位置开始查找 | 空闲分区以地址递增次序排列 | 不用每次都从低地址的小分区开始检索,算法开销小 |
参考文献:王道计算机考研-操作系统
一般像微博,各种社交软件,游戏等APP,都会有一个签到功能,连续签到多少天,送什么东西,比如:
设计一个签到记录表记录用户签到信息:
| uid | 连续签到天数 | 签到日期 | 签到类型 | 签到时间 |
|---|---|---|---|---|
| 1000 | 7 | 2021-09-03 | 补签 or 正常签到 | 2021-09-03 00:00:00 |
上述的签到表结构信息已经可以满足我们的签到业务实现,但是仔细分析,会有一些隐患:
解决不了流量突发问题,比如0点签到上万qps,mysql扛不住
补签和签到并行操作会出现连签计算问题
-
补签需要维护签到天数的更新,如果用户中间某一天断签了,补签后后续每一天都需要连续更新,接口响应耗时增大
解决方案:
mysql数据表按uid分表解决1 | UPDATE $table SET num = IF (last_checkin_time = 昨天, num + 1, 1) |
上述列出的三种解决方案看似解决了签到问题,但是还存在很多问题
比如问题一,分表虽然分担了并发读写单表的压力,但是补签产生批量更新的问题还是没解决,虽然问题三提出了使用消息队列来解决长任务执行问题,但是异步方案一是对用户体验不好,用户没办法实时看到补签效果,而且qps高的场景下,堆积问题明显,延时问题更严重,造成用户流失
问题二:多原子性的sql操作实现复杂,而且存在性能问题
问题三:同问题一的延时问题
此时,很明显,要满足上百、上千qps的签到业务,mysql业务显然已经满足不了了,要引入新的解决方案
那么是否可以直接套用业界秒杀问题解决方案呢?
先来看下秒杀场景:
所以我们必须选择一种能支撑高qps,并且并发读写性能都好的数据结构,而Redis恰好可以满足这个条件的
redis可以使用bitmap来解决高并发下的断签、补签问题
Redis-bitmap
比特位图是基于redis基本数据结构string的一种高阶数据类型。Bitmap支持最大位数2^32位。计算了一下,使用512M的内存就可以存储42.9亿的字节信息(2 ^32 -> 4294967296)

签到数据占用的内存也很小,查询统计的性能也不错,很好的解决了常规思路存在的问题。
bitmap来进行签到业务实现?已周期为月的签到日历为例:
签到
比如uid为1000的用户在2019-02-15月签到了一次,可以执行
1 | SETBIT u:sign:1000:201902 15 1 |
获取当天是否签到
1 | GETBIT u:sign:1000:201902 15 |
返回1即为当日已签到,返回0未签到
统计当月签到天数
1 | BITCOUNT u:sign:1000:201902 |
连签天数计算
1 | BITFIELD u:sign:1000:201902 get u28 0 |
201333251为当前签到位图的10进制转换,可以转换为二进制观察签到情况
201333251转换成二进制为1100000000000001101000000011
通过肉眼可观察出连续签到天数为最后两天(如果按后面日期推导,根据产品策略定)
我们可以通过程序的位运算来进行统计,以php为例:
1 |
|
实现原理很简单,就是对redis返回给我们的签到十进制数v进行左移在右移,对比是否和原值相同,相同说明未签到,不同则已签到,然后对v进行>>=,每次丢弃最低位达到逐位比较的目的
上面说的都是正常签到的情况,对与补签,我们只有计算出补签日期的偏移量,然后重新执行签到操作就可以了,由于连续签到天数是我们逐位对比计算的,所以不存在连签天数计算出错问题
虽然redis bitmap操作性能好,能满足高并发场景下的签到业务的签到、补签需求,但是由于没有签到业务数据明细,不利于数据分析和数据归档,这时,我们可以把mysql当作log使用,异步记录签到log,redis来支撑前端业务展示,
最后,如果我们的异步消息队列存在消息丢失,或者消息重发
对于消息丢失,我们可以做定期同步,比如,签到时,可以使用 set 数据结构来记录当日用户签到的uid集合,如果uid太多,可以将redis分key分布式存储,然后拿到set集合的uid去bitmap查询签到信息,然后同步到mysql,每日同步一次;
为了保证set集合操作和签到操作是原子性的,可以通过使用redis的lua脚本执行到达原子性
对于消息丢失,我们可以通过签到业务主健设计或者添加唯一索引来保证数据记录是幂等的
当计算机系统是多道程序设计系统时,通常会有多个进程或线程同时竞争cpu,只要有两个以上的进程处于就绪状态,并且只有一个cpu可用,那么就必须选择下一个要运行的进程
完成这项工作的这一程序称作调度程序,该程序使用的算法叫做调度算法
一旦进程开始执行,调度就在进程从运行状态切换到就绪状态以及从等待状态切换到就绪状态时发生,称为抢先调度。
在这种调度中,资源(CPU周期)会在短时间内分配给该进程,如果遇到某些优先级更高的进程,则可以暂停当前进程以处理该进程。
一旦进程开始执行,调度将在进程终止或进程从运行状态切换到等待状态时进行。
在非抢占式调度中,调度程序在执行过程中不会中断当前正在运行的进程。 但是它等待进程完成其与CPU的执行,然后可以将CPU分配给另一个进程。
抢占式调度在执行过程的中间,执行被中断,而; 在非抢占式调度中,在执行过程中不会中断执行。
使用队列数据结构实现
运行时间可以预知的非抢占式批处理调度算法,适用于所有作业都可同时运行
假设我们知道进程A,B,C,D的运行时间,A 8秒,B 4秒,C 4秒,D 4秒,由下图可知,选择B、C、D、A的顺序运行,平均等待时间最短
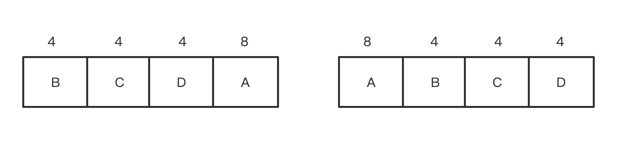
调度程序总是选择运行时间最短的那个进程优先执行
为每个进程分配一个时间片,进程在被允许的时间范围内执行,如果超出时间范围还在执行,cpu会剥夺该进程,并分配给另一个进程,如果进程提前执行完,cpu立即切换,是一种最公平、最简单的调度算法
时间片轮转会维护一张进程表,当一个进程用完它的时间片后,就会被移动到队列末尾
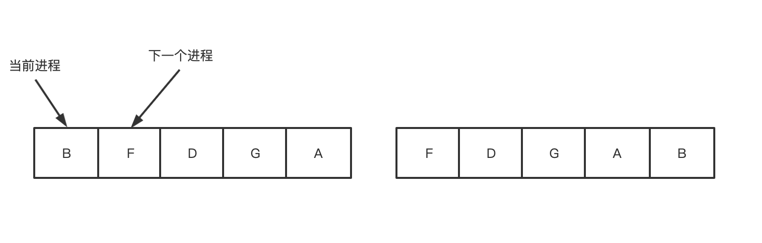
由于进程切换时,需要维护管理所需要的保存和装入的寄存器值及内存映像,各种更新表格和列表,会产生进程上下文切换,所以当时间片过短时,进程频繁切换,降低cpu效率,如果过长,会引起短的交互请求等待过程,通常时间片设置到20~50ms是比较合适的折中
维护优先级队列,每个进程被分配优先级权重,按优先级高低分配到优先级队列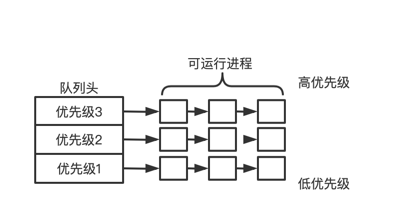
多级队列调度算法将就绪队列分成多个单独队列。根据进程属性,如内存大小、进程优先级、进程类型等,一个进程永久分到一个队列,每个队列有自己的调度算法。
队列之间划分时间片
对于批处理系统而言,由于最短作业通常可以伴随着最短相应时间,所以如果被应用到交互式系统中,那将是非常好的,而最短进程就可以看作是最短作业被应用到交互式系统
保证调度算法是另外一种类型的调度算法,它向用户所做出的保证并不是优先运行,而是明确的性能保证,该算法可以做到调度的公平性。
一种比较容易实现的性能保证是处理机分配的公平性。如果在系统中有n个相同类型的进程同时运行,为公平起见,须保证每个进程都获得相同的处理机时间1/n
彩票数(ticket)代表了进程(或用户或其他)占有某个资源的份额。一个进程拥有的彩票数占总彩票数的百分比,就是它占有资源的份额。
实时系统通常可以分为硬实时和软实时,前者的含义是必须满足绝对的截止时间,后者的含义是虽然不希望偶尔错失截止时间,但是可以容忍。在这两种情形中,实时性能都是通过把程序划分为一组进程而实现的,其中每个进程的行为是可预测和提前掌握的。这些进程一般寿命较短,并且极快地就运行完成。在检测到一个外部信号时,调度程序的任务就是按照满足所有截止时间的要求调度进程。
实时系统中的事件可以按照响应方式进一步分类为周期性(以规则的时间间隔发生)事件或非周期性(发生时间不可预知)事件。一个系统可能要响应多个周期性事件流。根据每个事件需要处理时间的长短,系统甚至有可能无法处理完所有的事件。例如,如果有m个周期事件,事件i以周期Pi发生,并需要Ci秒CPU时间处理一个事件,那么可以处理负载的条件是
c1/p1+c2/p2+......+cm/pm≤1
满足这个条件的实时系统称为是可调度的。
作为一个例子,考虑一个有三个周期性事件的软实时系统,其周期分别是100ms、200ms和500ms。如果这些事件分别需要50ms、30ms和100 ms的CPU时间,那么该系统是可调度的,因为 0.5 + 0.15 + 0.2 < 1。如果有第四个事件加入,其周期为1秒,那么只要这个事件是不超过每事件150ms的CPU时间,那么该系统就仍然是可调度的。在这个计算中隐含了一个假设,即上下文切换的开销很小,可以忽略不计。
实时系统的调度算法可以是静态或动态的。前者在系统开始运行之前作出调度决策;后者在运行过程中进行调度决策。只有在可以提前掌握所完成的工作以及必须满足的截止时间等全部信息时,静态调度才能工作。而动态调度算法不需要这些限制。
用户态和内核态是操作系统的两种运行状态,操作系统主要是为了对访问能力进行限制,用户态的权限较低,而内核态的权限较高
当应用程序调用系统服务时、如读取文件内容,会发生如下调用过程
read代码通过汇编插入到寄存器,然后将操作系统控制由用户空间切换到内核空间read系统调用,执行完成后将操作系统控制转交给用户空间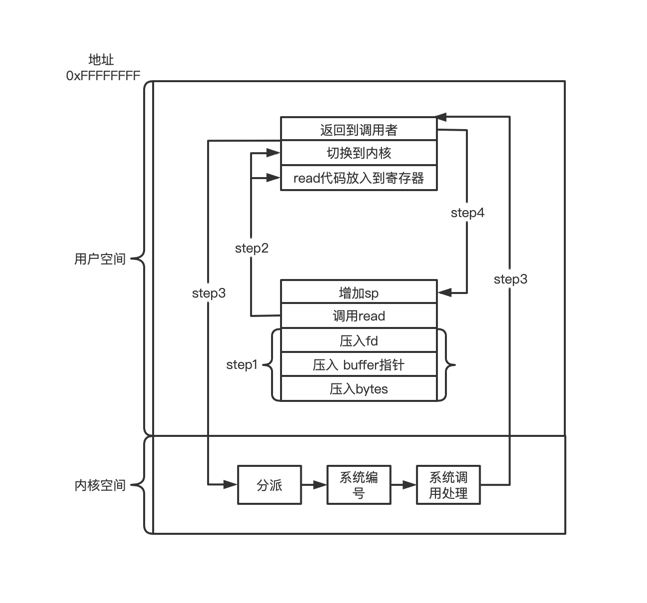
步骤3中,系统调用可能会阻塞调用者,比如试图读取键盘输入信息,如果没有键入,就会发生阻塞,稍后、当需要的键入输入时,操作系统会通知进程,之后会继续执行后面的流程
参考文献:现代操作系统
进程为操作系统提供了伪(并行)的能力,线程提高了操作系统伪(并行)的能力,没有进程和线程,现代计算是不复存在的
以下内容均为UNIX操作系统中描述
在进程模型中,所有在计算机上可运行的软件,包括操作系统,被组织成若干顺序进程,简称进程
一个进程包含程序计数器、寄存器和变量当前的值,从概念上来讲,每个进程拥有自己的cpu,实际上是cpu在进程间不断的切换导致的错觉,这种快速切换称为多道程序设计
对于用户进程,其既有用户地址空间中的栈,也有它自己的内核栈。而内核进程就只有内核栈。
| 每个进程的内容 |
|---|
| 地址空间 |
| 全局变量 |
| 打开文件 |
| 子进程 |
| 定时器 |
| 信号和信号处理程序 |
| 账户信息 |
采用多道程序设计可提高cpu的利用率
cpu利用率计算公式:1-p^n
p表示进程等待时间和运行时间的之比,n表示多道程序设计的道数
例如:一个8g内存的操作系统,操作系统占了2G,每个应用程序占了2G,假如每个应用程序80%的时间都处于IO等待,那么cpu利用率等于1-0.8^3约为49%
这时候,增加8g内存,运行程序数量,可从3道程序设计提高到7道,cpu利用率为1-0.8^7,cpu利用率提升到79%
如果在增加8g内存,cpu利用率只能由79%提升到91%,显然不如之前的第一种投资好
进程创建主要通过系统调用fork函数来实现的,调用后会创建后会创建一个与调用进程相同的副本,称之为子进程,这两个进程拥有相同的内存镜像,他们拥有各自不同的地址空间,其中不可写的内存区域是可共享的。可写的内存区是不共享的,通过写时复制共享
进程终止由以下几个条件引起
前两种状态是类似的,区别是第二种状态没有分配cpu资源,第三种状态与前两种不同,处于该状态进程不能运行,即使cpu是空闲的
操作系统维护一个表格(结构数组或链表)即进程表,该表包含了进程状态的重要信息,包括程序各种状态转换时必须保存的信息,从而保证进程再次启动时,像从未中断过一样
| 进程管理 | 存储管理 | 文件管理 |
|---|---|---|
| 寄存器 | 正文段指针 | 根目录 |
| 程序计数器 | 数据段指针 | 工作目录 |
| 程序状态字 | 堆栈段指针 | 文件描述符 |
| 堆栈指针 | 用户id | |
| 进程状态 | 组id | |
| 优先级 | ||
| 调度参数 | ||
| 进程id | ||
| 父进程 | ||
| 进程组 | ||
| 信号 | ||
| 进程开始时间 | ||
| 使用cpu的时间 | ||
| 子进程cpu时间 | ||
| 下次定时器时间 |
线程是cpu执行的最小单元,比进程更轻量级,更容易创建或撤销
线程也包含程序计数器、寄存器和自己的堆栈
进程中的不同线程不像不同进程那样存在很大的独立性,所有的线程都有完全一样的地址空间,这意味着它们可以共享全局变量
| 每个线程的内容 |
|---|
| 程序计数器 |
| 寄存器 |
| 堆栈 |
| 状态 |
每个线程拥有自己的堆栈,原因是:
线程调用时需要使用栈帧存放局部变量和调用后返回的地址,而每个线程调用的过程是不同,要单独维护一套自己的执行历史
需要多线程的原因有两个,
同进程一样,线程也可以处于运行、阻塞、就绪或终止状态
整个线程包处于用户空间,从内核角度考虑,就是按正常单进程单线程方式管理,这种方式好处是有些操作系统内核不支持多线程,也可以一样使用多线程模型
用户空间线程除了这点好处,还有以下几点优势:
当然,它也有一些不可避免的缺点:
内核线程在操作系统内核中保存了每个线程的寄存器、状态、和其他信息,跟用户空间线程是一样的,区别是保存在了内核中
内核线程的管理工作由操作系统内核完成,这种实现的好处是当一个线程阻塞时,内核根据选择,可以切换到进程内另一个线程
如果当某个线程引发了页面故障,内核可以很方便的检测是否有其他可用的线程,让其执行
虽然内核解决了线程很多问题,但也不会解决所有问题,比如当一个新进程创建,是将进程里的所有线程都复制,还是只有一个线程?
还有一个问题是当过来一个信号,可以交给需要的线程执行,当时多个线程都注册了该信号,会发生什么?
混合实现主要分为用户线程和内核线程多对1、1对1、和多对多模式,其中多对1模式就是前面介绍的在用户空间实现的线程模型,线程中使用阻塞时会阻塞其他线程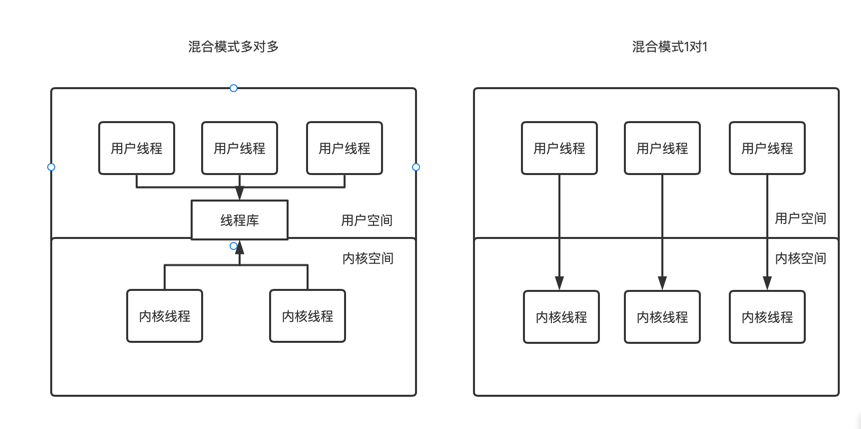
混合模式解决了多对多和1对1模型解决了线程没办法使用阻塞问题,但是1对1模型会占用多个内核线程,对操作系统内核切换影响比较大,第三种多对多模型是并发效果最好的
进程通常需要与其他进程通信,以达到信息传递并能保证进程按照正确顺序执行
多个进程读写某个共享数据,而最后的结果取决于进程运行的精准时序,称为竞争条件
怎样避免竞争条件?主要目标是组织多个进程同时读取共享数据,即互斥
抽象描述就是,我们把共享内存进行访问的程序片段叫做临界资源或者临界区,我们只要保证两个进程不同时在临界区,就能避免竞争
尽管避免竞争条件,我们还是不能保证数据共享的并发进程能高效的执行:对于一个好的解决方案,需要满足以下条件
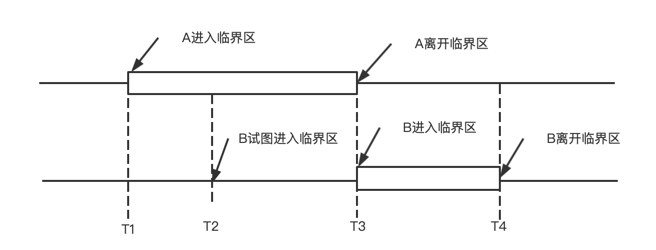
对于理想的方案应该是如上图这样的,某一时刻对与临界区的访问只能有一个进程
最简单的实现方案,当进程进入临界区时,立即屏蔽所有中断,在离开之前打开中断,屏蔽中断后,cpu时钟中断也会屏蔽,cpu只有在发生时钟中断或其他中断时才会切换进程,这样,屏蔽中断后cpu不会切换进程,不必担心其他进程的介入
这个方案并不好,对于单核cpu,执行屏蔽中断如果不在打开,系统会因此而终止,对于多核cpu,仅对执行disable的那个cpu优先,其他cpu仍继续执行
实现方案为设计一个锁变量,其值为0,如果有其他程序进入到临界区,会将值赋值为1,这样,其他进程读到1就不会在访问临界区了
这种方案也会出现疏忽,即两个进程同时进入临界区时,读到的临界变量都是0,执行了两次赋值1的操作,但还是发生了资源竞争
进程a:
1 | while(true) { |
进程b:
1 | while(true) { |
一开始,进程a和b拿到的trun都是0,这时,只有进程a能进入并修改turn为1,这时进程b由于turn一直为0,会不断等待,直到turn变成1,这种忙等待行为被称为自旋锁
这种方式如果两个进程的执行速度会相差很多,轮流进入时会有一方等待很长时间,显然是不合适的
1 |
|
在使用共享变量时(即进入其临界区)之前,各个进程使用各自的进程号 0 或 1 作为参数来调用 enter_region,这个函数调用在需要时将使进程等待,直到能够安全的临界区。在完成对共享变量的操作之后,进程将调用 leave_region 表示操作完成,并且允许其他进程进入。
现在来看看这个办法是如何工作的。一开始,没有任何进程处于临界区中,现在进程 0 调用 enter_region。它通过设置数组元素和将 turn 置为 0 来表示它希望进入临界区。由于进程 1 并不想进入临界区,所以 enter_region 很快便返回。如果进程现在调用 enter_region,进程 1 将在此处挂起直到 interested[0] 变为 FALSE,这种情况只有在进程 0 调用 leave_region 退出临界区时才会发生。
那么上面讨论的是顺序进入的情况,现在来考虑一种两个进程同时调用 enter_region 的情况。它们都将自己的进程存入 turn,但只有最后保存进去的进程号才有效,前一个进程的进程号因为重写而丢失。假如进程 1 是最后存入的,则 turn 为 1 。当两个进程都运行到 while 的时候,进程 0 将不会循环并进入临界区,而进程 1 将会无限循环且不会进入临界区,直到进程 0 退出位置。
TSL指令是一个需要硬件支持的方案。TSL称为测试并加锁(test and set lock)。他将一个内存字LOCK读到寄存器RX中。然后在该内存地址上存一个非零值。读字和写字操作是不可分割的,即该指令结束前其他处理器均不允许访问该内存字。执行TSL指令的CPU将锁住内存中线,以禁止其他CPU在本指令结束前访问内存。TSL指令解决了忙等待的屏蔽中断方案中无法屏蔽多处理器访问共享内存的问题。 因为锁住内存总线不同于屏蔽中断,锁住内存总线后,所有处理器都无法通过内存总线访问内存字。 那些多处理器的计算机都有TSL指令。如下
1 | TSL RX, LOCK |
1 | enter_region: |
具体工作过程:第一条指令将lock原来的值复制到寄存器中并将lock设置为1,随后这个原来的值与0相比较。如果原来的值非零,则说明以前已被加锁,则程序将回到开始并再次测试。经过一段时间后,lock值变为0,于是过程返回,此时已加锁。要清除这个锁比较简单,程序只需将0存入lock即可,不需要特殊的同步指令。
一个可替代TSL的指令是XCHG,它原子性地交换两个位置的内容,例如,一个寄存器与一个存储字。它本质上与TSL的解决办法一样。所有的Intel x86 CPU在底层同步中使用XCHG指令。
上述基于忙等待的互斥,不仅会浪费CPU时间,而且还可能引起预想不到的结果。例如,有两个进程L和H,L的优先级较低、H的优先级较高。调度规则规定,只要H处于就绪态它就会运行。在某一时刻,L处于临界区中,此时H变到就绪态,准备运行。现在H开始忙等待,待由于H就绪时,L就不会被调度,也就无法离开临界区,所以H将永远忙等待下去。这种情况有时被称作优先级反转问题。
最简单的进程间通信原语,它们在无法进入临界区时将阻塞,而不是忙等待。两条最简单的通信原语是:sleep和wakeup。sleep是一个将引起调用进程阻塞的系统调用,即被挂起,直到另外一个进程将其唤醒。wakeup调用有一个参数,即要被唤醒的进程。
基于支持P、V操作的非负整数实现。
信号量的用处一:生产者-消费者问题
在使用信号量的系统中,隐藏中断的最自然的方法就是为每一个I/O设备设置一个信号量,其初始值为0。在启动一个I/O设备之后,管理进程就立即对相关联的信号量执行一个Down操作,于是进程立即被阻塞。当终端到来时,终端处理程序随即对相关信号量执行一个Up操作,从而将相关的进程设置为就绪状态。
为了解决生产者-消费者问题,可以使用三个信号量:full, 用于记录充满的缓冲槽数据;empty,用于记录空的缓冲槽总数;mutex,用来确保生产者和消费者不会同时访问缓冲区。
信号量的用处二:用于实现同步(Synchronization)
信号量full和empty用来保证某种时间的顺序发生或不发生。例如,当缓冲区满的时候生产者停止运行,而空的时候消费者停止运行。
互斥量是一个可以处于两态之一的变量:加锁、解锁。相比于信号量,它没有计数功能。
由于互斥量非常简单,所以如果有TSL或XCHG指令,就可以很容易地在用户空间中实现它们。由于用户级线程包的mutex_lock和mutex_unlock代码下(0表示解锁):
1 | mutex_lock: |
mutex_lock的代码与enter_region的代码很相似,但有一个关键的区别。当enter_region进入临界区失败后,它始终重复测试锁(忙等待)。实际上,由于时钟超时的作用,会调度其它进程运行,这样迟早拥有锁的进程会进入运行并释放锁。
在用户线程中,情形有所不同,因为没有时钟停止运行时间长度的线程。结果就是通过忙等待的方式来试图获取锁的线程将永远循环下去,绝不会得到锁,因为这个运行的线程不会让其它线程运行从而释放锁。
这就是enter_region与mutex_lock的区别
pthread中提供了基于互斥锁的同步机制。提供的函数如下:
1 | pthread_mutex_init(); // 创建互斥锁 |
pthread中处理提供了互斥锁,还提供了条件变量用于实现同步。互斥量在允许或阻塞对临界区的访问上是很有用的,条件变量则允许线程由于一些未达到的条件而阻塞。绝大多数情况下,这两种方法是一起使用的。下面就是线程、互斥量、条件变量之间的关联。
信号量机制存在的问题:编写程序困难、易出错
能不能设计一种机制,让程序员写程序时不需要再关注复杂的PV操作,让写代码更轻松呢?
1973年,Brinch Hansen首次在程序设计语言(Pascal) 中引入了“管程”成分――一种高级同步机制
管程是一种特殊的软件模块,有这些部分组成:
局部于管程的共享数据结构说明;
对该数据结构进行操作的一组过程;
对局部于管程的共享数据设置初始值的语句;
管程有一个名字。
管程的基本特征:
局部于管程的数据只能被局部于管程的过程所访问;
一个进程只有通过调用管程内的过程(函数)才能进入管程访问共享数据;
每次仅允许一个进程在管程内执行某个内部过程。
参考文献:现代操作系统

主节点:192.168.205.10
从节点1:192.168.205.11
从节点2:192.168.205.12

1 | docker swarm init --advertise-addr 192.168.205.10 |
复制提示的命令到其它两个容器中执行


查看node信息
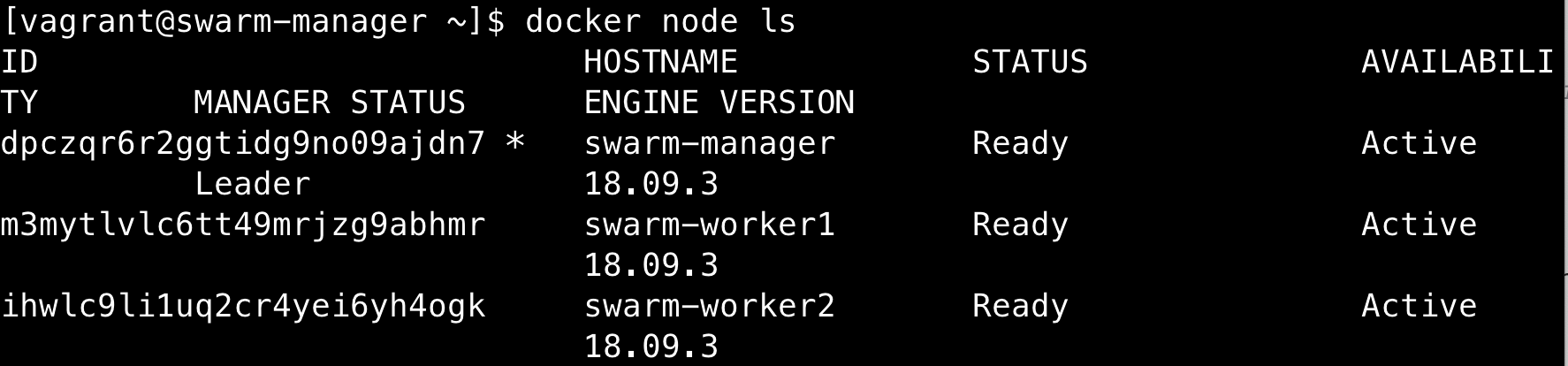
1 | docker service COMMAND |
1 | docker service create --name demo busybox /bin/sh -c "while true; do sleep 3600; done" |
查看容器详细信息
1 | docker service ls |

replicated表明可以横向扩展
1 | docker service scale demo=5 |

5/5表示5个都已经ready/共5个scale
swarm 分布情况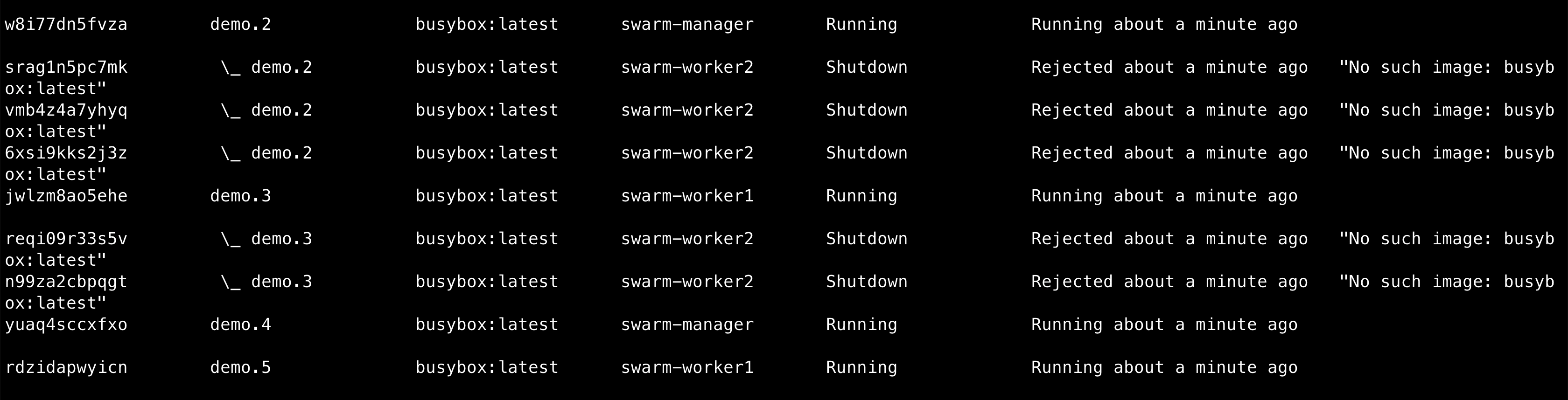
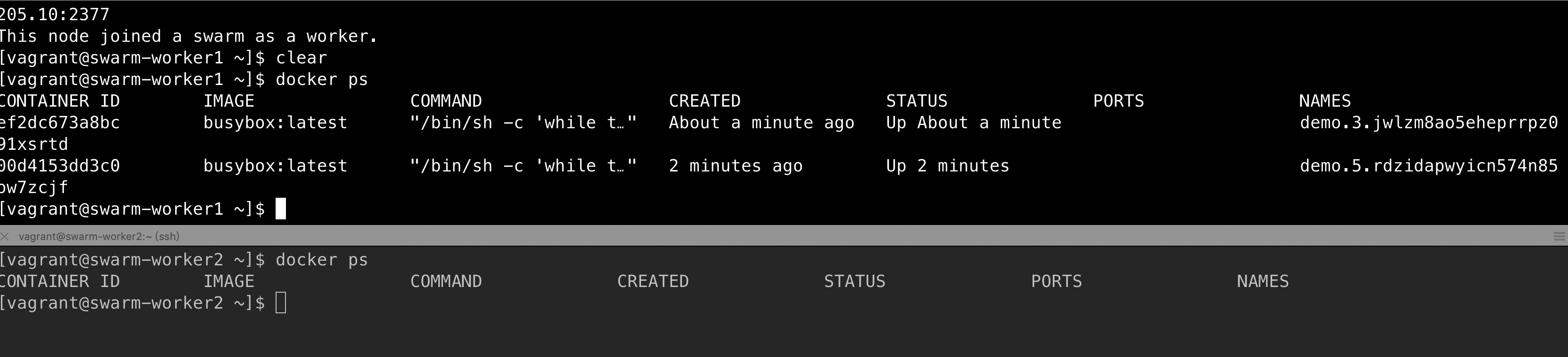
删除swarm
1 | docker service rm demo |
1 | //创建overlay网络 |
创建mysql service
1 | docker service create --name mysql --env MYSQL_ROOT_PASSWORD=root --env MYSQL_DATABASE=wordpress --network demo --mount type=volume,source=mysql-data,destination=/var/lib/mysql mysql:5.7 |
创建wordpress service
1 | docker service create --name wordpress -p 80:80 --env WORDPRESS_DB_PASSWORD=root --env WORDPRESS_DB_HOST=mysql --network demo wordpress |
部署成功
此时访问集群中任意一台机器的ip都可以访问到wordpress,实际上,docker在swarm中建立了一个虚拟ip来实现通信,关于通信方式可参考routingmesh
作用:
ENDPOINT_MODE: vip | dnsrr
vip 通过lvs负载均衡虚拟ip的方式(默认推荐使用)
dnsrr:dns负载均衡轮询策略
lables是起到帮助信息的作用
1 | version: "3" |
mode: global | replicated(默认)
replicated可以做横向扩展,global不可以
node.role == manager 指定部署在swarm manager节点上
constraints 一些限制条件
1 | version: '3.3' |
在mode:replicated下有效
replicas: 6 部署6个service
1 | version: '3' |
(cpu_shares, cpu_quota, cpuset, mem_limit, memswap_limit, mem_swappiness)的一些资源设置
1 | version: '3' |
表示redis服务被限制使用不超过50M的内存和0.50(50%)的可用处理时间(CPU),并保留20M的内存和0.25 CPU时间(始终可用)
1 | version: "3" |
表示服务停止时最大尝试次数为3,重启时间间隔是5秒,重启是否成功之前需要等待120s时间
parallelism:最多可以同时update2个replicas,每次只能更新一个
delay:每次更新之间的间隔时间,
order: 更新期间的操作顺序。stop-first(旧任务在启动新任务之前停止)或start-first(新任务首先启动,正在运行的任务短暂搁置)(默认stop-first)注意:只支持v3.4或更高版本。
1 | version: '3.4' |
详情参考compose-file
sudo mkdir -p /usr/docker-vol/mysql/data
vim docker-compose.yml
1 | version: '3' |
1 | docker stack deploy wordpress --compose-file=docker-compose.yml |
docker stack services wordpress 查看service准备情况
docker stack ls 列举stack
docker stack ps wordpress 查看wordpress运行情况
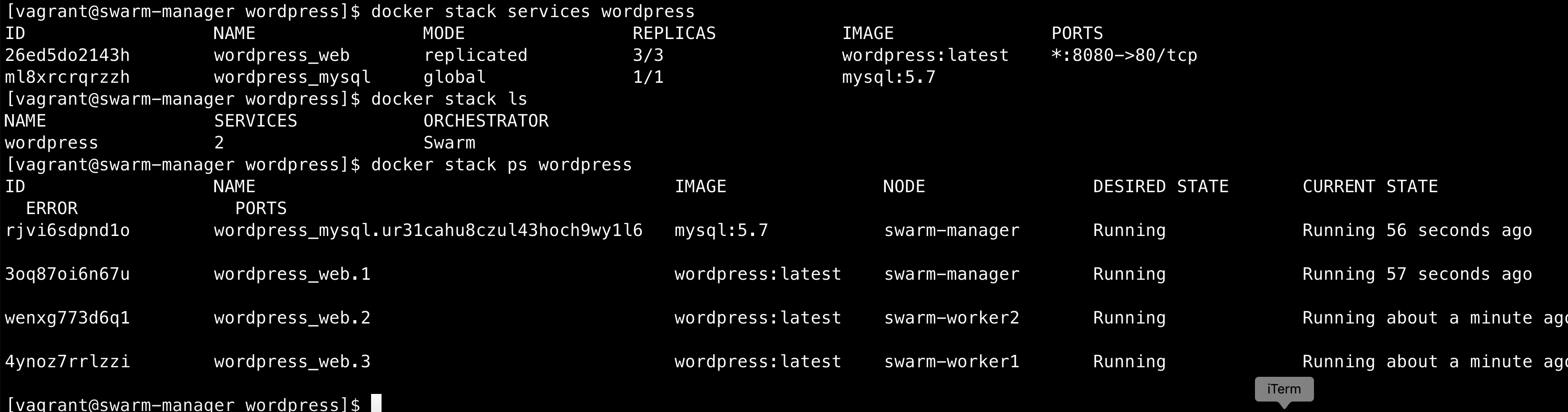
看到如下界面配置成功
清空环境
1 | docker stack rm wordpress |