栈内存(协程栈、调用栈)
- go的协程栈位于go堆内存上
- go堆内存位于操作系统虚拟内存上
主要作用:
- 协程的执行路径
- 局部变量
- 函数参数
- 返回值
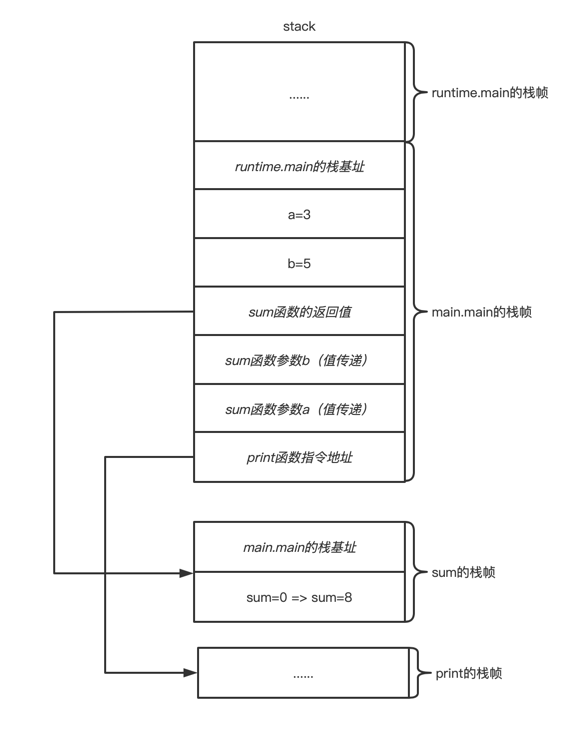
下面的go程序简述了协程栈的工作流程
1 | func sum(a, b int) { |
参数传递
- Go使用参数拷贝(深拷贝)
- 传递结构体会拷贝结构体全部内容
- 传递结构体指针,会拷贝结构体指针
协程栈作用总结
- 协程栈记录了协程的执行现场
- 协程栈还记录局部变量,函数参数和返回值
- Go的函数参数是值传递
协程栈不够大怎么办?
引起协程栈不够大的主要原因:
- 本地变量太多
- 栈帧太多
本地变量太多
当协程栈空间不够大会通过变量从栈逃逸到堆上来得到缓解,因而产生逃逸问题
- 指针逃逸
- 函数返回了对象的指针go build -gcflags=-m escape.go
1
2
3
4
5
6
7
8
9func point() *int {
a := 0
return &a
}
func main() {
i := point()
fmt.Println(i)
}1
2
3
4
5
6
7# command-line-arguments
./escape.go:5:6: can inline point
./escape.go:11:12: inlining call to point
./escape.go:12:13: inlining call to fmt.Println
./escape.go:6:2: moved to heap: a
./escape.go:11:12: moved to heap: a
./escape.go:12:13: ... argument does not escape
- 函数返回了对象的指针
- 空接口逃逸
- 如果函数的参数是
interface,函数的实参很可能会逃逸1
2
3
4
5
6
7
8func intf() {
b := 0
fmt.Println(b)
}
func main() {
intf()
}1
2
3
4
5
6go build -gcflags=-m escape.go
# command-line-arguments
./escape.go:7:13: inlining call to fmt.Println
./escape.go:10:6: can inline main
./escape.go:7:13: ... argument does not escape
./escape.go:7:13: b escapes to heap因为
interface{}类型的函数往往使用反射,反射往往要求反射的对象在堆上
- 如果函数的参数是
- 大变量逃逸
- 一般在64位机器,超过
64k的变量会发生逃逸
- 一般在64位机器,超过
逃逸原因
- 不是所有的变量都能放在协程栈
- 栈帧回收后,需要继续使用的变量
- 变量太大
栈帧太多
go的栈初始大小为2k,必要时会对栈进行扩容,在1.13版本前使用分段栈,后期使用连续栈
分段栈
优点:没有空间浪费
缺点:伸缩时栈指针会在不连续的空间来回反复横跳
连续栈
优点:空间是连续的
缺点:伸缩时开销大,需要将旧空间拷贝过来,所以当空间不足发生扩容时,变为原来的2倍
为了减少伸缩时的开销,当空间使用率不足1/4时,变为原来的1/2
堆内存
在64位操作系统中
- Go每次申请的虚拟内存单元位
64MB - 最多有
2^20虚拟内存单元 - 内存单元也叫
headArena - 所有的
headArena组成了mheap(Go堆内存)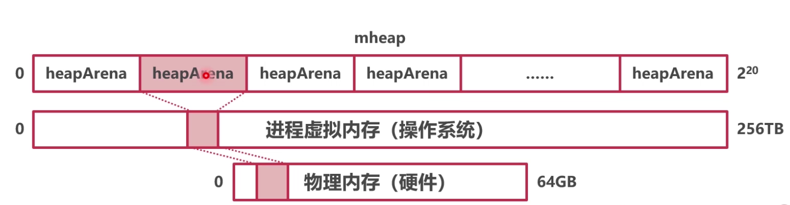
操作系统虚拟内存的最大容量是由计算机的地址结构(CPU寻址范围)确定的,虛拟内存的实际容量=min(内存和外存容量之和,CPU寻址范围)
如:某计算机地址结构为32位,按字节编址,内存大小为512MB,外存大小为2GB。 则虚拟内存的最大容量为2^32B= 4GB
虚拟内存的实际容量 =min (2^32B,512MB+2GB)=2GB+512MB
headArena分配方式
- 线性分配(线性顺序分配)
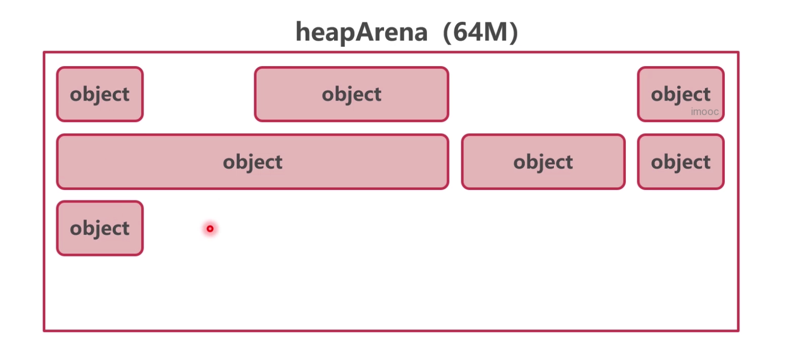
- 链表分配
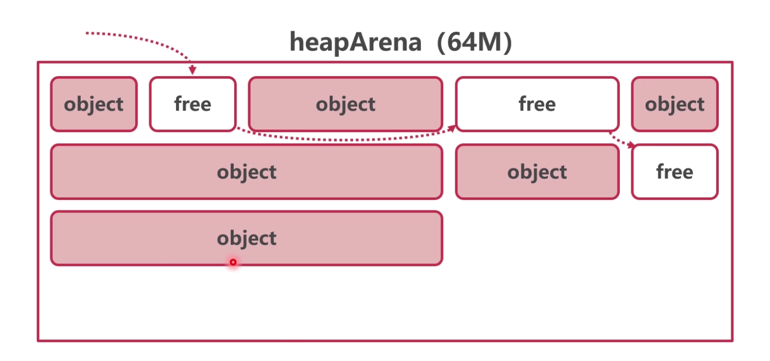
- 分级分配
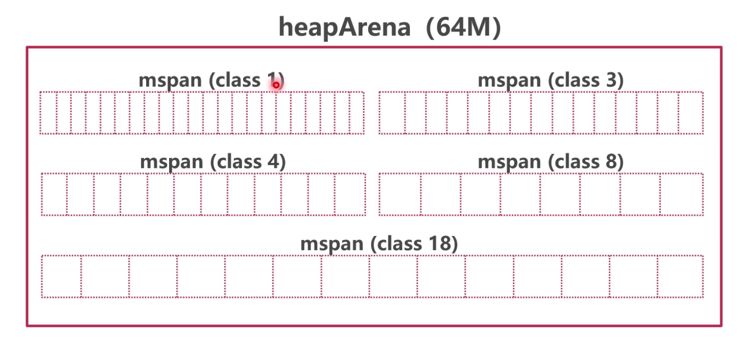
分级分配可以看成将内存整理成不同规格按需进行分配
线性分配和链表分配都会产生外部内存碎片
内存管理单元mspan
mspan是内存最小使用单位- 每个
mspan为N个相同大小的“格子 - 一共有67中
mspan
mspan规格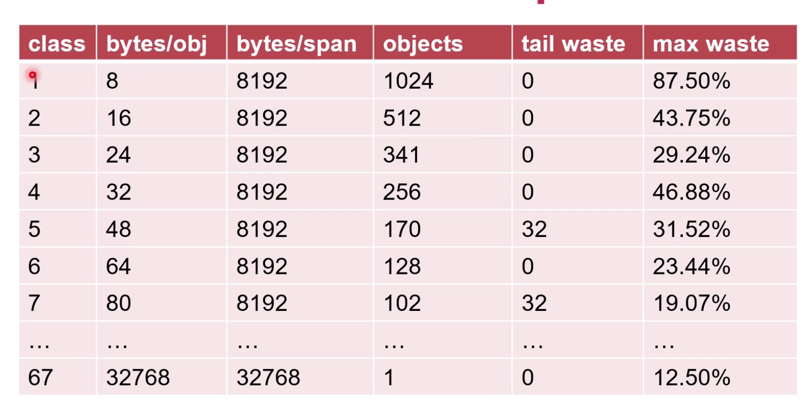
中心索引(mcentral)
go分配内存时为了达到按需分配,通过中心索引能实现快速查找到所需规格的内存,mcentral被放在mspan链表头
- 共需要有134个
mcentral - 67个组用来标记需要
GC扫描的mspan,如堆中的对象 - 67个组用来标记不需要
GC扫描的mspan,如常量
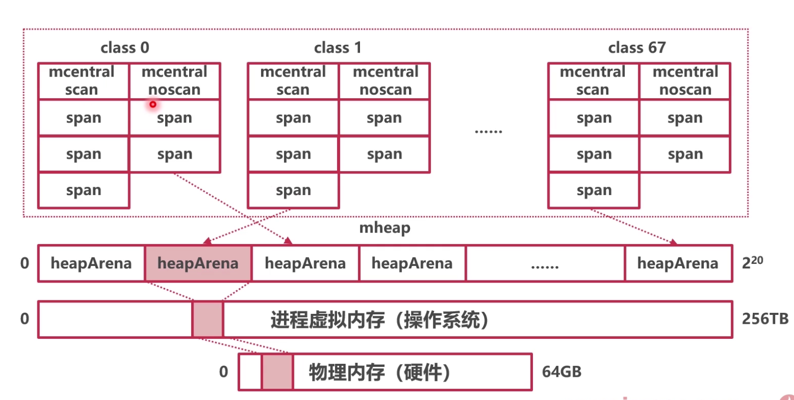
mcentral性能问题
mcentral使用互斥锁保护- 高并发场景下存在锁冲突
- 参考协程
GMP模型,增加线程本地缓存
线程缓存mcache(本地缓存)
- 每个
P拥有一个mcache1
2
3
4
5
6
7
8
9
10
11type p struct {
id int32
status uint32 // one of pidle/prunning/...
link puintptr
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
...
} - 一个
mcache拥有134种mspan,67个需要GC的和67个不需要GC的mspan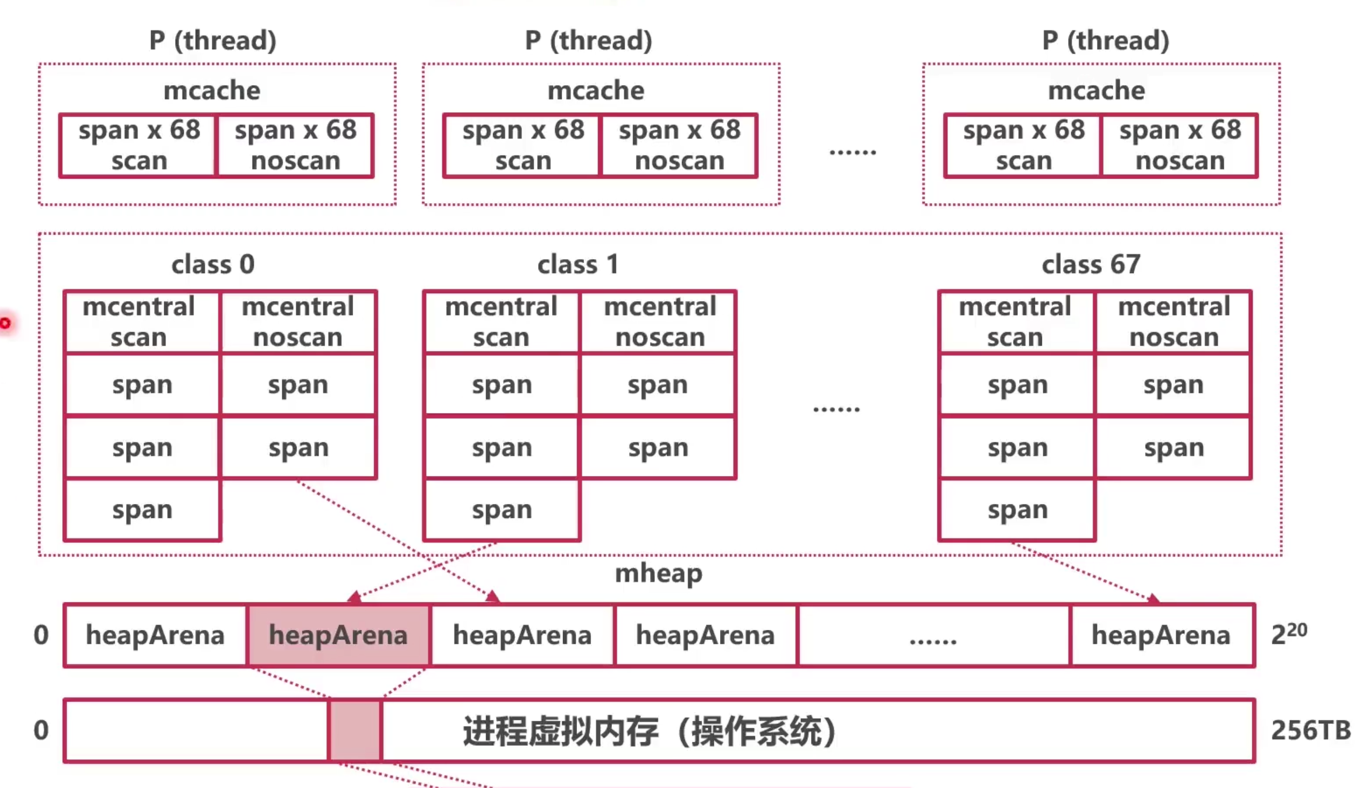
headArena结构总结
- GO使用
heapArena向操作系统申请内存 - 使用
heapArena时,以mspan为单位,防止碎片化 mcentral是mspan们的中心索引mcache记录了分配给各个P的本地mspan
对象分级
Go分配内存时变量对象分为3个级别
Tiny微对象无指针(<16B以内)Small小对象(16k-32k之间)Large大对象无指针(>32K以上)- 微小对象分配至普通的
mspan(class1~class67)- 从
mcache拿到class2级别mspan - 多个微对象合并成一个
16byte存入到mspan(class2)的一个小单元
- 从
- 大对象分配至0级
mspan(class0)
垃圾回收
什么样对象需要垃圾回收
垃圾回收思路
- 标记-清除
- 标记后直接清除
- 优点:逻辑简单
- 问题:会有内存碎片产生
- 标记-整理
- 将碎片化内存整理后,清除多余的碎片
- 优点,没有内存碎片
- 问题:整理过程cpu开销大
- 标记-复制
- 复制一块新的内存,然后将旧的内存块上标记的内存整理到新的内存块上
- 优点,无内存碎片,内存复制快
- 问题:浪费空间
Go因为有独特的内存结构规格管理优势,直接选择最简单的标记-清除
标记
把根数据段上的数据作为root,基于他们进行进一步的追踪,追踪到的数据就进行标记,最后把没有标记的对象当作垃圾进行释放,是Go的GC的核心原理
- 被栈上的指针引用(逃逸到堆上的内存变量)
- 被全局变量指针引用
- 被寄存器指针引用
- 上述变量被称为
Root Set(GCROOT)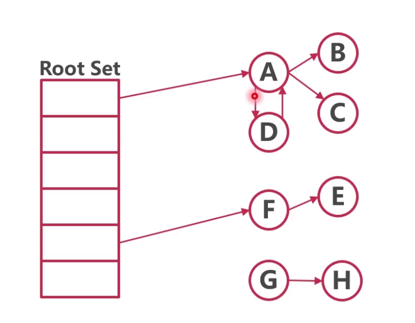
通过DFS搜索除了G和H剩下的都不能GC掉
GC方式
首先一个重要的概念:
STW:stop the word,指程序执行过程中,中断暂停程序逻辑,专门去进行垃圾回收。
串行GC
- 开启STW
- 通过DFS找到无用内存
- 释放堆内存
- 停止STW
并行GC
Go采用三色标记法实现并行GC
黑色:有用已经分析扫描
黑色:有用还未分析扫描
白色:暂时无用
三色标记法
三色标记法过程
起初所有堆上的对象都是白色的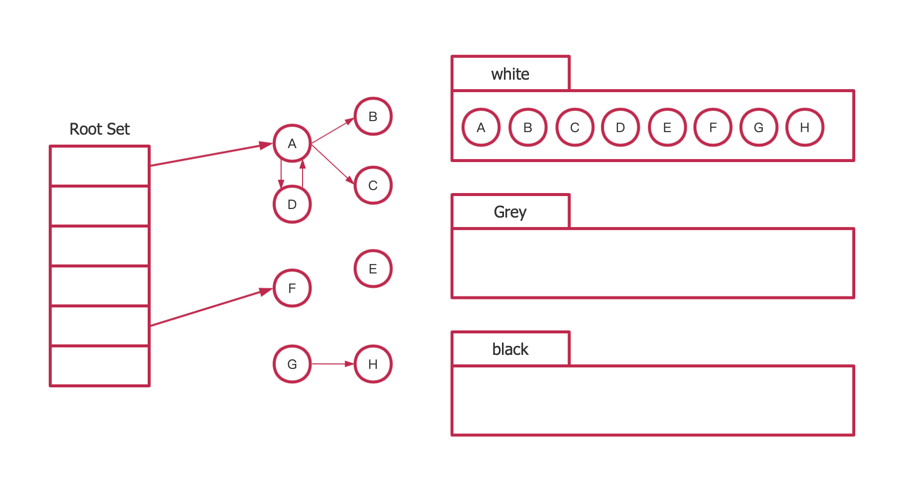
GC开始,遍历堆栈root,将直接可达的对象标记为灰色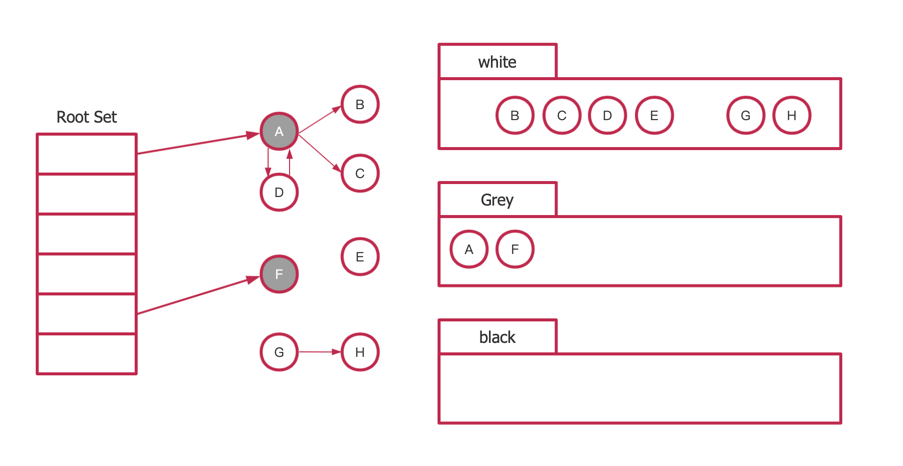
遍历灰色结点,将直接可达的对象标记为灰色,自身标记为黑色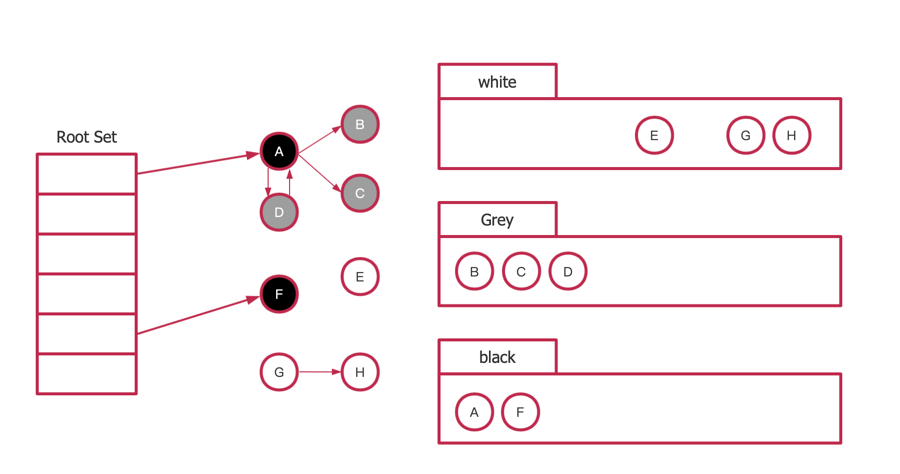
继续执行第三步同样的步骤,直到所有能够访问到的结点都被标记为黑色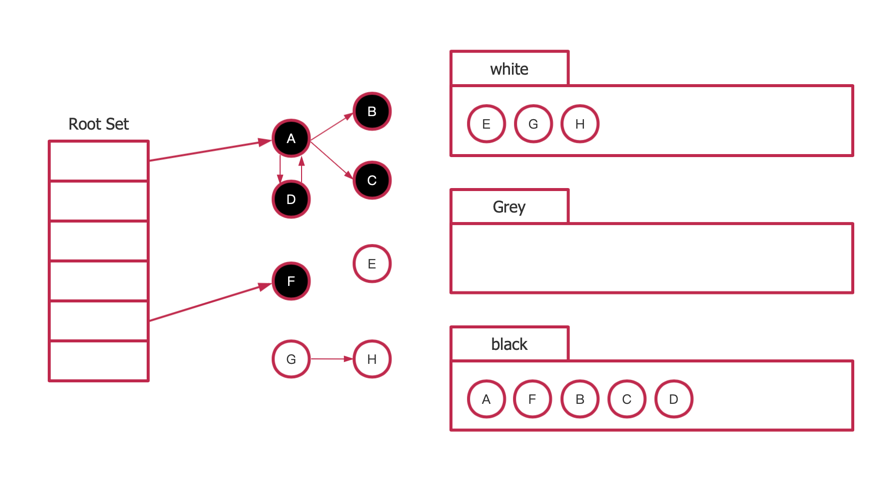
回收所有白色标记的对象。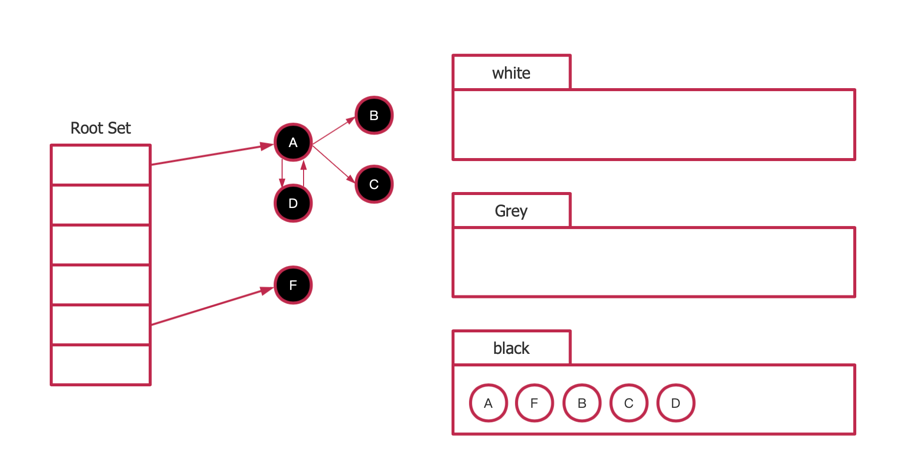
再次标记时,所有对象恢复为白色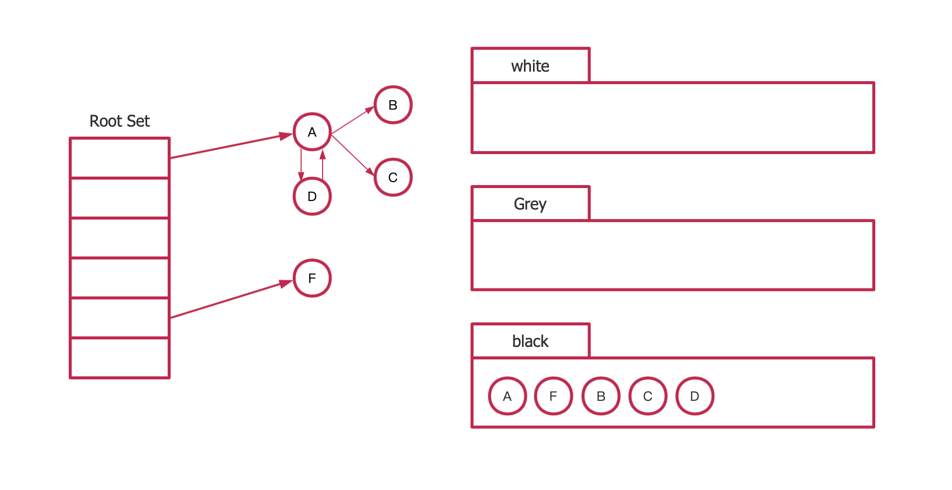
三色标记法并行时的问题
三色标记法在并发标记过程中会出现误回收情况:
由于是并发执行过程,如果不开启STW,GC分析过的某个白色标记,此时被业务代码进行了新的引用,被引用到之前的一个灰色的标记对象,那么此时这个变量应该就不是白色了,但是由于GC已经分析过前面的变量引用关系了,就不会把这个变量标记成灰色和黑色,导致误回收
初始状态的对象结构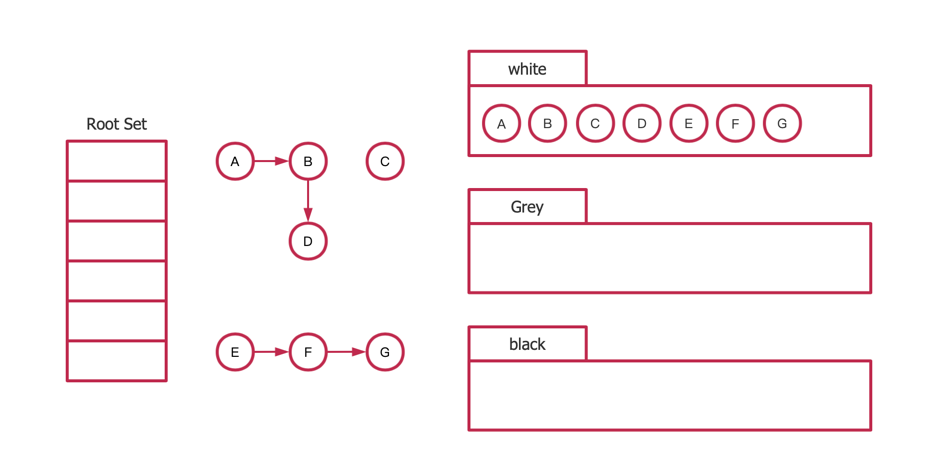
C在标记中间时中被E引用,由于E是一开始就被分析过了,所以不再会重新分析E,导致C被误回收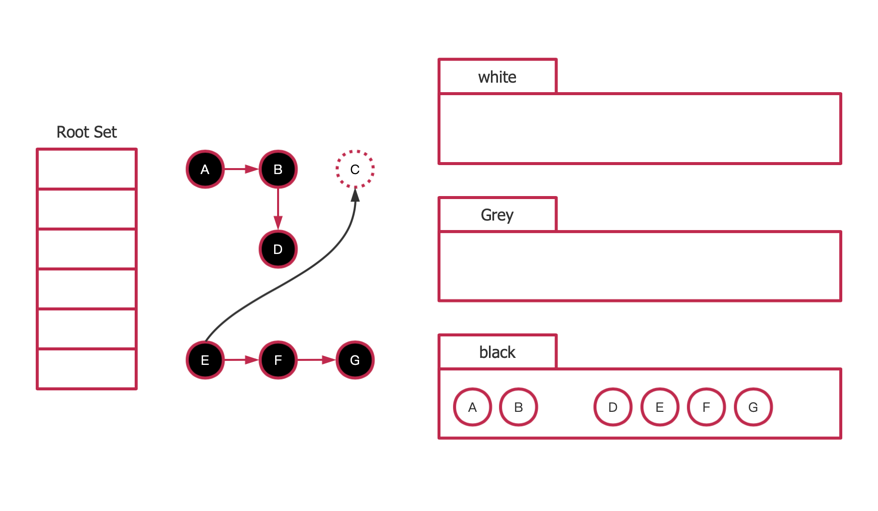
删除写屏障
原理:当一个白色对象被另外一个对象时解除引用时,将该被引用对象标记为灰色(白色对象被保护)
缺点:如上面的例子,如果一开是B指向了C,B和C在断开后才会将C标记为白色,由于上述示例C在一开始就没有被引用过,所以不会被标记为黑色
插入写屏障
原理:当一个对象引用另外一个对象时,将另外一个对象标记为灰色。
插入写屏障可以杜绝堆空间新增的被引用的指针误回收的情况;
但是由于栈容量小,反应速度要求高,不能用插入屏障的机制。因此,在堆对象扫描完之后,为了不引发误回收,会对栈对象STW,然后通过三色并发标记清扫,完成GC。
混合写屏障
可以看到之前的插入屏障和删除屏障有明显的自身缺陷:
插入屏障:需要对栈对象重新STW遍历
删除屏障:回收精度低
GO 1.8采用了混合写屏障,混合写屏障,就是结合两者优势,又中和两者的劣势。混合写屏障减少STW,并且减少了扫描栈对象的时间。混合写屏障会做如下操作:
- GC开始时,将栈全部可达对象标记为黑色
- GC期间,任何在栈上新创建的对象,均为黑色。
将栈上的可达对象全部标黑,扫描过程中,如果某个groutine栈的对象出现引用关系变更,进行STW,但是不会对整个栈STW - 被删除的对象标记为灰色
- 被添加的对象标记为灰色
总结
GoV1.8三色标记法加混合写屏障机制,栈空间不启动屏障机制,堆空间启动屏障机制。整个过程几乎不需要STW,效率较高。
GC优化
尽量减少堆上的垃圾
- 内存池化
- 减少逃逸
- 尽量使用空结构体
观察GC
1 | GODEBUG=gctrace=1 ./main |
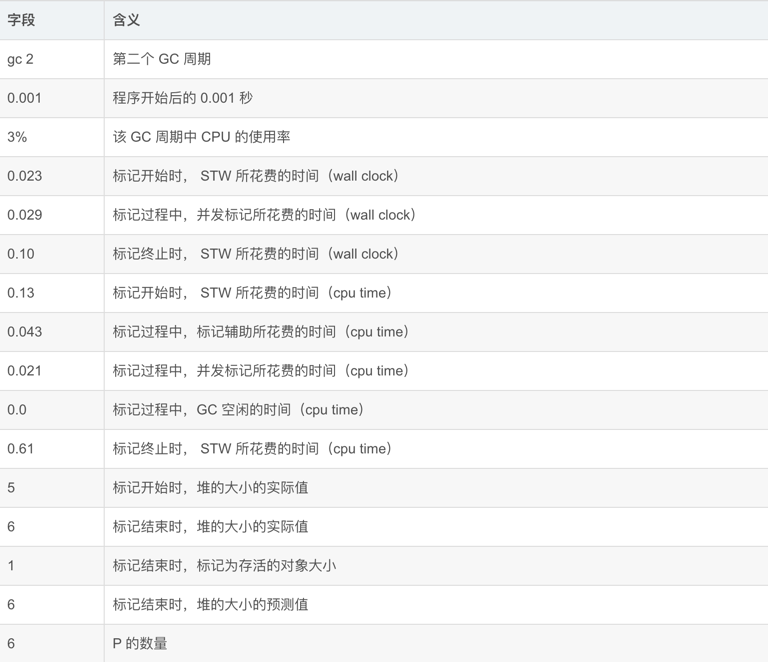
字段含义: