入门介绍 安装 ElasticSearch需要的jdk版本至少是1.8的,所以安装之前先查看jdk版本号 2.下载ElasticSearch
1 2 3 wget https://github.com/elastic/elasticsearch/archive/v6.5.0.tar.gz tar -zxvf elasticsearch-6.5.0.tar.gz cd elasticsearch-6.5.0
简单本地集群环境搭建
vim config/elasticsearch.yml
1 cluster.name: my-application 注释打开
启动三个集群命令
1 2 3 ./bin/elasticsearch -Ehttp.port=7200 -Epath.data=node3 ./bin/elasticsearch -Ehttp.port=8200 -Epath.data=node2 ./bin/elasticsearch
集群状态查看
1 2 3 4 5 6 7 pengshiliang@pengshiliang-OptiPlex-3020:~$ curl 127.0.0.1:9200/_cat/nodes?v ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 127.0.0.1 30 98 2 2.03 0.96 0.53 mdi - dRA_DV4 127.0.0.1 30 98 2 2.03 0.96 0.53 mdi - j8_g2SD 127.0.0.1 31 98 3 2.03 0.96 0.53 mdi * 3cYY9cL pengshiliang@pengshiliang-OptiPlex-3020:~$ curl 127.0.0.1:9200/_cluster/stats {"_nodes" :{"total" :3,"successful" :3,"failed" :0},"cluster_name" :"my-application" ,"cluster_uuid" :"5nD6JB_MRyiin3n7QTCoDg" ,"timestamp" :1552028850410,"status" :"green" ,"indices" :{"count" :0,"shards" :{},"docs" :{"count" :0,"deleted" :0},"store" :{"size_in_bytes" :0},"fielddata" :{"memory_size_in_bytes" :0,"evictions" :0},"query_cache" :{"memory_size_in_bytes" :0,"total_count" :0,"hit_count" :0,"miss_count" :0,"cache_size" :0,"cache_count" :0,"evictions" :0},"completion" :{"size_in_bytes" :0},"segments" :{"count" :0,"memory_in_bytes" :0,"terms_memory_in_bytes" :0,"stored_fields_memory_in_bytes" :0,"term_vectors_memory_in_bytes" :0,"norms_memory_in_bytes" :0,"points_memory_in_bytes" :0,"doc_values_memory_in_bytes" :0,"index_writer_memory_in_bytes" :0,"version_map_memory_in_bytes" :0,"fixed_bit_set_memory_in_bytes" :0,"max_unsafe_auto_id_timestamp" :-9223372036854775808,"file_sizes" :{}}},"nodes" :{"count" :{"total" :3,"data" :3,"coordinating_only" :0,"master" :3,"ingest" :3},"versions" :["6.5.0" ],"os" :{"available_processors" :12,"allocated_processors" :12,"names" :[{"name" :"Linux" ,"count" :3}],"mem" :{"total_in_bytes" :24839368704,"free_in_bytes" :437612544,"used_in_bytes" :24401756160,"free_percent" :2,"used_percent" :98}},"process" :{"cpu" :{"percent" :0},"open_file_descriptors" :{"min" :305,"max" :306,"avg" :305}},"jvm" :{"max_uptime_in_millis" :74396,"versions" :[{"version" :"1.8.0_171" ,"vm_name" :"Java HotSpot(TM) 64-Bit Server VM" ,"vm_version" :"25.171-b11" ,"vm_vendor" :"Oracle Corporation" ,"count" :3}],"mem" :{"heap_used_in_bytes" :972703928,"heap_max_in_bytes" :3116630016},"threads" :143},"fs" :{"total_in_bytes" :483753484288,"free_in_bytes" :438342832128,"available_in_bytes" :413745967104},"plugins" :[],"network_types" :{"transport_types" :{"security4" :3},"http_types" :{"security4" :3}}}}
多机部署 1 2 network.host: your ip discovery.zen.ping.unicast.hosts: ["$ip " ] $ip 一定要包含该集群中其他机器的ip
Elasticsearch 常用术语 Document 文档数据
CRUD Create request 1 2 3 4 5 6 POST /accounts/person/1 { "name": "Bob", "job": "developer", "sex": "male" }
这条语句表述的含义是在index为accounts的person类型下创建一条id为1的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "_index" : "accounts" , "_type" : "person" , "_id" : "1" , "_version" : 1 , "result" : "created" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } , "_seq_no" : 0 , "_primary_term" : 1 }
GET request Result:
1 2 3 4 5 6 7 8 9 10 11 12 { "_index" : "accounts" , "_type" : "person" , "_id" : "1" , "_version" : 1 , "found" : true , "_source" : { "name" : "Bob" , "job" : "developer" , "sex" : "male" } }
Update request 1 2 3 4 5 6 POST /accounts/person/1/_update { "doc": { "name": "John" } }
Result:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "_index" : "accounts" , "_type" : "person" , "_id" : "1" , "_version" : 2 , "result" : "updated" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } , "_seq_no" : 1 , "_primary_term" : 2 }
Delete request 1 DELETE /accounts/person/1
Result:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "_index" : "accounts" , "_type" : "person" , "_id" : "1" , "_version" : 5 , "result" : "deleted" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } , "_seq_no" : 4 , "_primary_term" : 2 }
查询语法 Query String 后面接?q形式
request 1 GET /accounts/person/_search?q=John
Query Dsl request 1 2 3 4 5 6 7 8 GET /accounts/person/_search { "query": { "match": { "name": "John" } } }
详细参考query-dsl
ElasticSearch初步介绍 正排/倒排索引 正排索引:
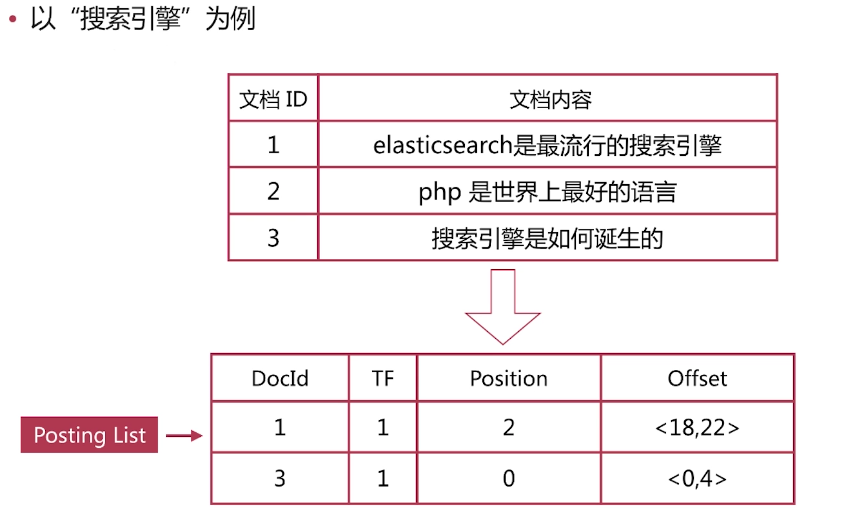
文档ID 文档内容 1 elasticsearch是最流行的搜索引擎 2 php是世界最好的语言 3 搜索引擎是如何诞生的
倒排索引:
文档内容 文档ID elasticsearch 1 流行 1 搜索引擎 1,3 php 2 世界 2 最好 2 语言 2 如何 3 诞生 3
查询包含搜索引擎的文档:
通过倒排索引获得含有“搜索引擎”的文档ID是1,3 通过正排索引查看1,3的内容 返回结果 倒排索引基本概念 倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
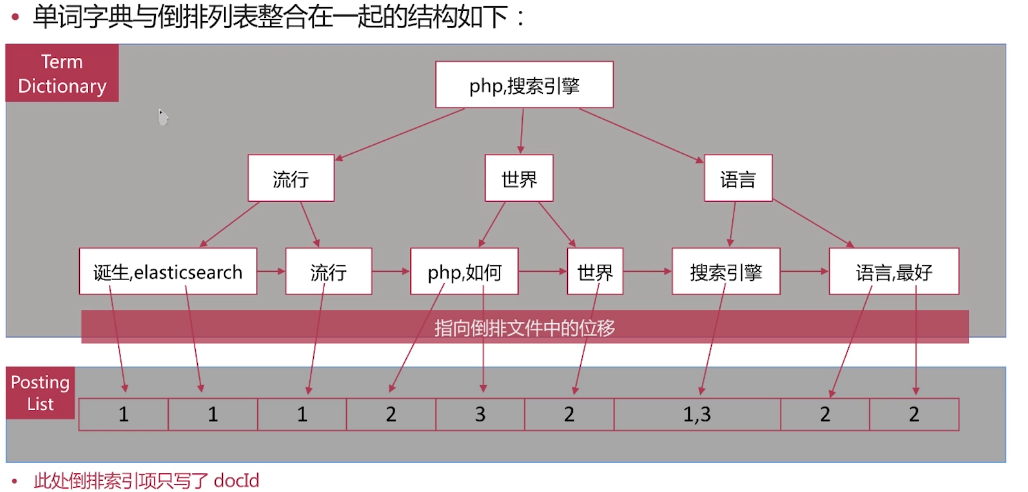
倒排索引的组成 倒排索引是搜索引擎的核心,主要包含两个部分:
单词词典(Trem Dictionary):记录的是所有的文档分词后的结果 倒排列表(Posting List):记录了单词对应文档的集合,由倒排索引项(Posting)组成。 单词字典的实现一般采用B+Tree的方式,来保证高效
倒排索引项(Posting)主要包含如下的信息:
文档ID,用于获取原始文档的信息 单词频率(TF,Term Frequency),记录该单词在该文档中出现的次数,用于后续相关性算分。 位置(Position),记录单词在文档中的分词位置(多个),用于做词语搜索。 偏移(Offset),记录单词在文档的开始和结束位置,用于高亮显示 倒排列表:
“elasticsearch是最流行的搜索引擎”可分为3个词语,搜索引擎在第二个位置,并且字符位置是18-22之间
es存储的是一个json格式的文档,其中包含多个字段,每个字段都会有自己的倒排索引,类似这种
1 2 3 4 { "username" : "huangtoufa" , "job" : "programmer" }
job和username都有自己的倒排索引
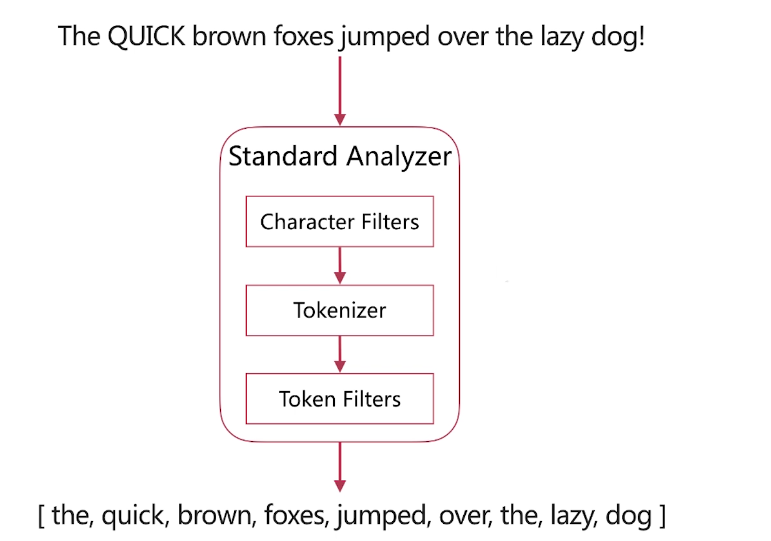
分词介绍 分词是指将文本转换成一系列单词( term or token )的过程,也可以叫做文本分析,在es里面称为Analysis
·分词器是es中专门处理分词的组件,英文为Analyzer ,它的组成如下
分词调用顺序:
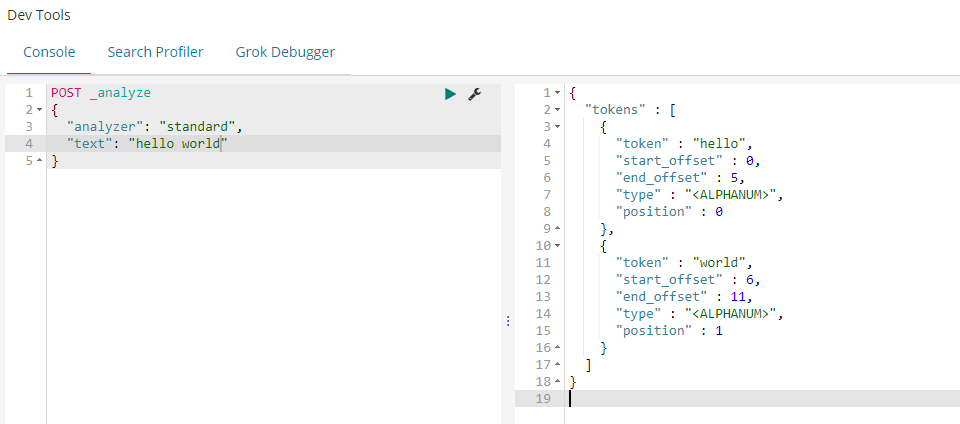
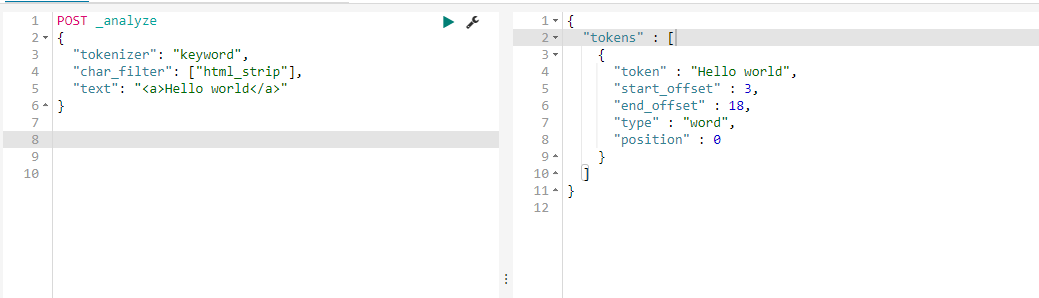
analyze_api es提供了一个测试分词的api接口,方便验证分词效果, endpoint是_analyze
关键词解释:
analyzer:分词器
当没有定义analyzer的时候会使用默认分词器”analyzer”:”standard”
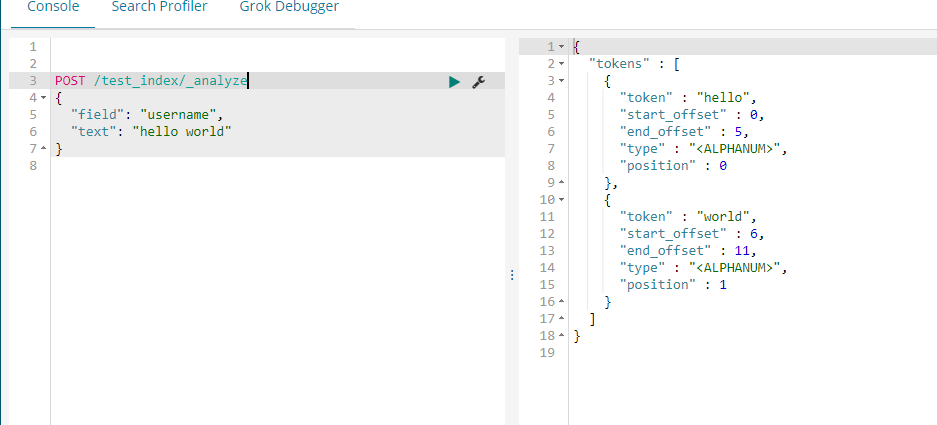
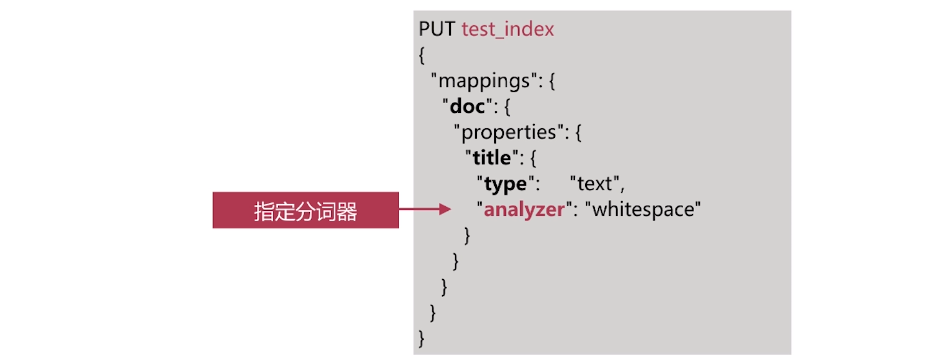
指定field分词:
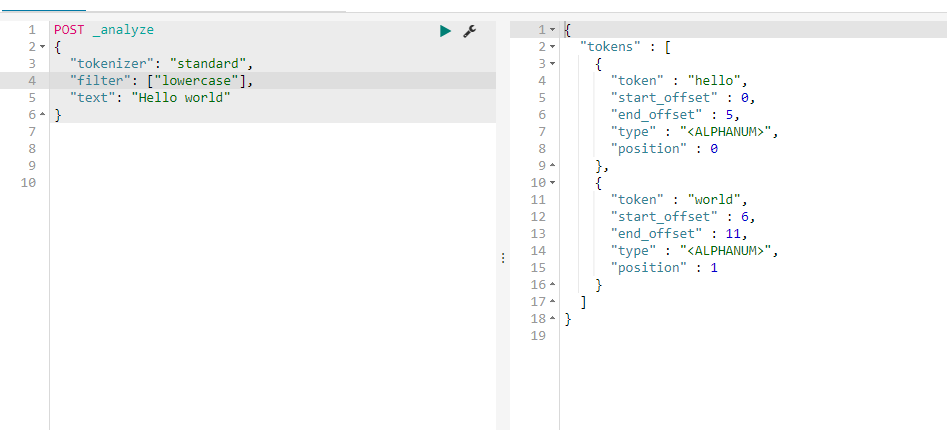
自定义分词器:tokenizer指名要用哪个分词器,filter指明的是token filter:
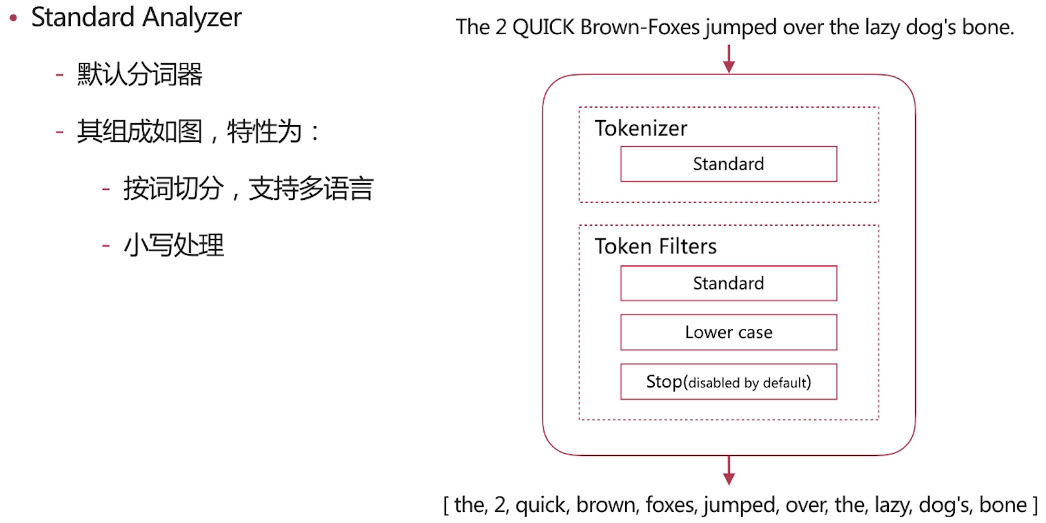
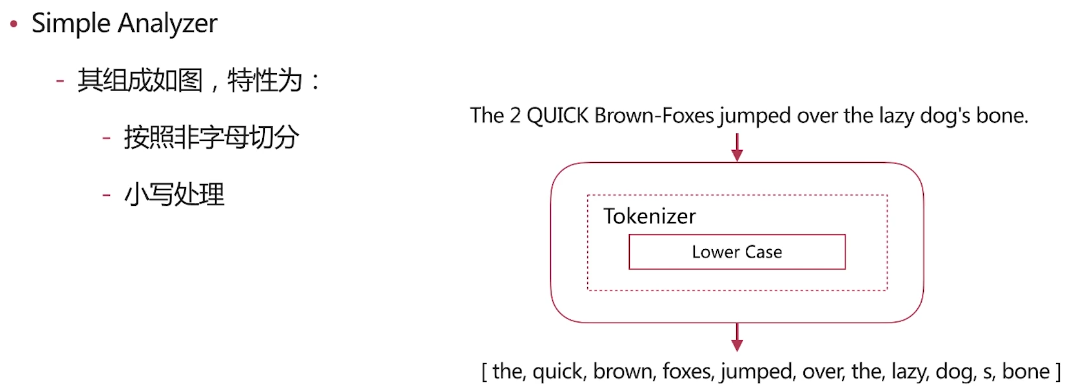
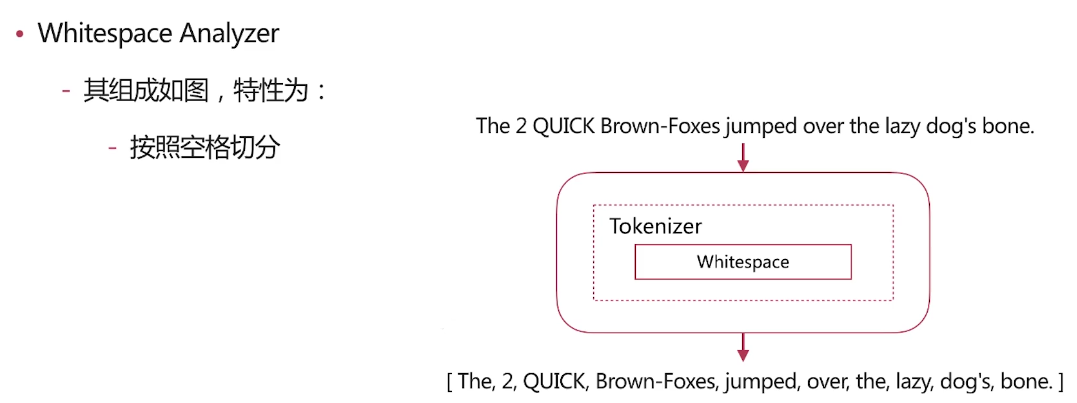
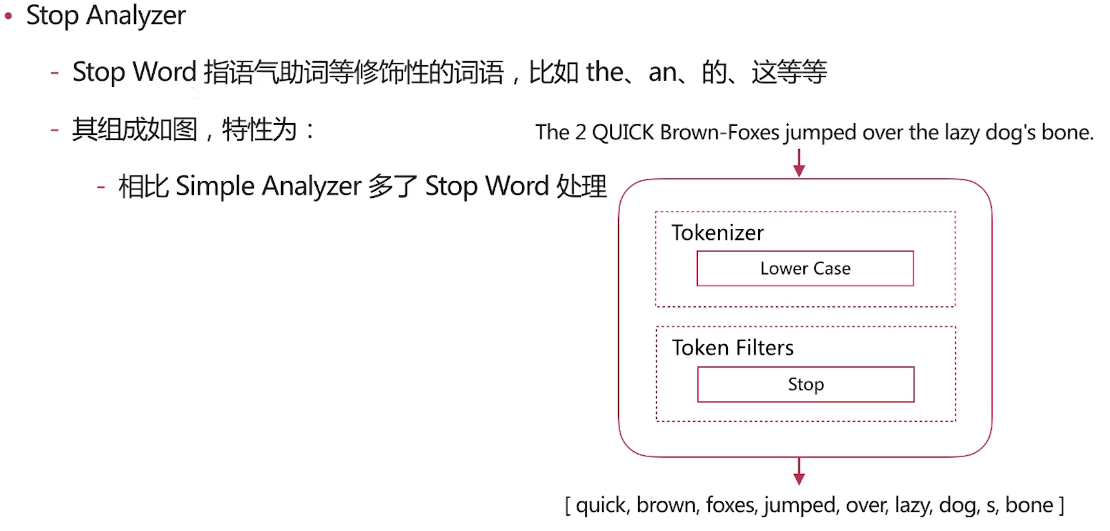
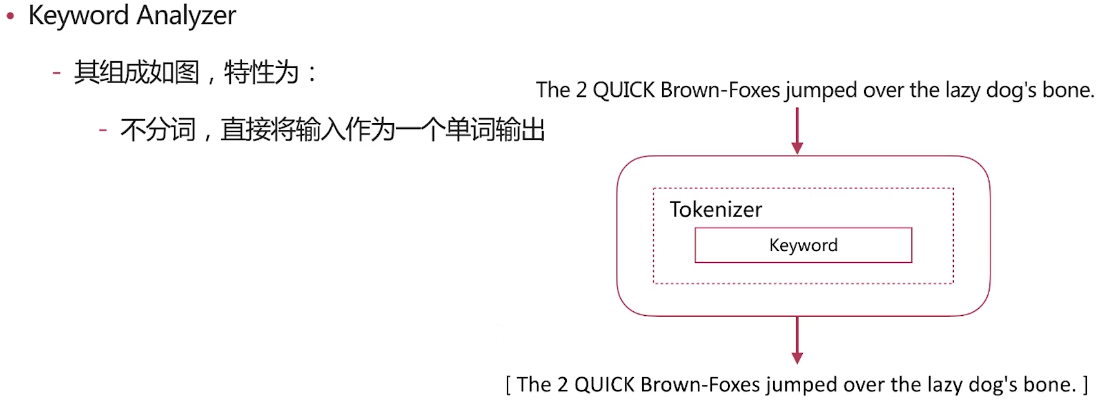
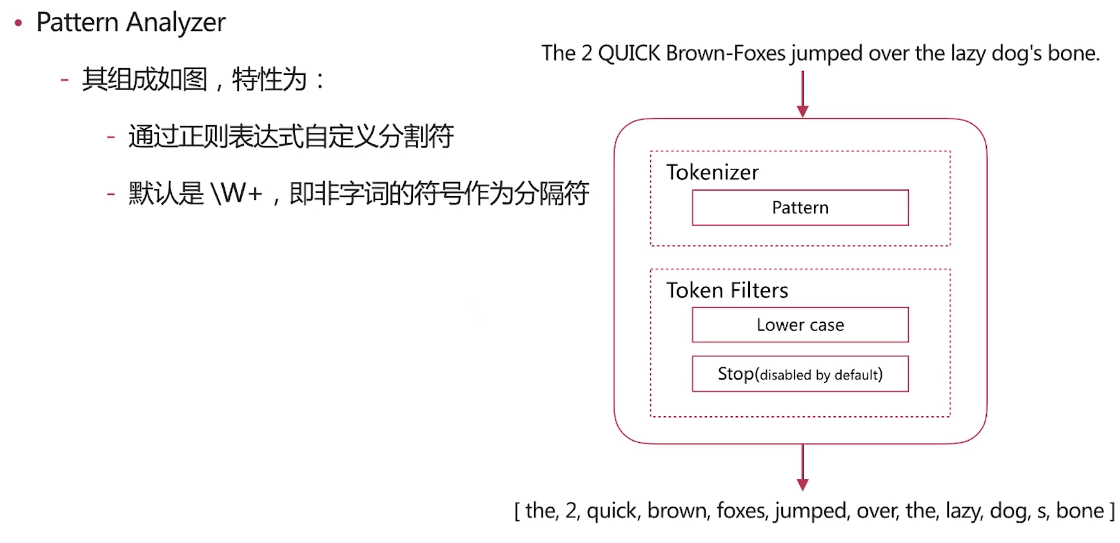
自带分词器 es自带如下的分词器
中文分词 ·难点
·常用分词系统https://github.com/medcl/elasticsearch-analysis-ik https://github.com/sing1ee/elasticsearch-jieba-plugin https://github.com/hankcs/HanLP https://github.com/microbun/elasticsearch-thulac-plugin
自定义分词 CharacterFilter:
当自带的分词无法满足需求时,可以自定义分词
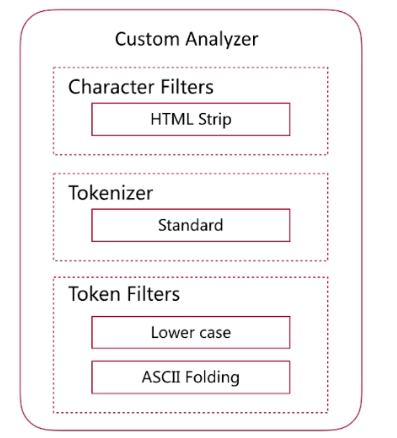
通过自定义Character Filters, Tokenizer和Token Filter实现. Character Filters 在Tokenizer之前对原始文本进行处理,比如增加、删除或替换字符等 自带的如下:HTML Strip去除html标签和转换html实体 Mapping进行字符替换操作 Pattern Replace进行正则匹配替换 会影响后续tokenizer解析的postion和offset信息 Character Filters测试时可以采用如下api :
Tokenizer:
将原始文本按照一定规则切分为单词( term or token ) 自带的如下:standard按照单词进行分割 letter按照非字符类进行分割 whitespace按照空格进行分割 UAX URL Email按照standard分割,但不会分割邮箱和url NGram和Edge NGram连词分割 Path Hierarchy按照文件路径进行切割 api:
request 1 2 3 4 5 POST _analyze { "tokenizer": "path_hierarchy", "text": "one/two/three" }
Result:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "tokens" : [ { "token" : "one" , "start_offset" : 0 , "end_offset" : 3 , "type" : "word" , "position" : 0 } , { "token" : "one/two" , "start_offset" : 0 , "end_offset" : 7 , "type" : "word" , "position" : 0 } , { "token" : "one/two/three" , "start_offset" : 0 , "end_offset" : 13 , "type" : "word" , "position" : 0 } ] }
TokenFilter:
对于tokenizer输出的单词( term )进行增加、删除、修改等操作 自带的如下:lowercase将所有term转换为小写 stop删除stop words NGram和Edge NGram连词分割 Synonym添加近义词的term api:
request 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 POST _analyze { "tokenizer": "standard", "text": "a Hello, world!", "filter": [ "stop", "lowercase", { "type": "ngram", "min_gram": 4, "max_gram": 4 } ] }
Result:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 { "tokens" : [ { "token" : "hell" , "start_offset" : 2 , "end_offset" : 7 , "type" : "<ALPHANUM>" , "position" : 1 } , { "token" : "ello" , "start_offset" : 2 , "end_offset" : 7 , "type" : "<ALPHANUM>" , "position" : 1 } , { "token" : "worl" , "start_offset" : 9 , "end_offset" : 14 , "type" : "<ALPHANUM>" , "position" : 2 } , { "token" : "orld" , "start_offset" : 9 , "end_offset" : 14 , "type" : "<ALPHANUM>" , "position" : 2 } ] }
Custorm:
创建自定义分词器:
request 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 PUT test_index { "settings": { "analysis": { "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "standard", "char_filter": [ "html_strip" ], "filter": [ "lowercase", "asciifolding" ] } } } } }
request 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 { "test_index" : { "aliases" : { } , "mappings" : { } , "settings" : { "index" : { "number_of_shards" : "5" , "provided_name" : "test_index" , "creation_date" : "1552462361614" , "analysis" : { "analyzer" : { "my_custom_analyzer" : { "filter" : [ "lowercase" , "asciifolding" ] , "char_filter" : [ "html_strip" ] , "type" : "custom" , "tokenizer" : "standard" } } } , "number_of_replicas" : "1" , "uuid" : "novqTjprQE24bJPdtxydCA" , "version" : { "created" : "6050099" } } } } }
自定义分词验证:
request 1 2 3 4 5 POST test_index/_analyze { "analyzer": "my_custom_analyzer", "text": "<a>This is a <b>Text</b></a>" }
分词结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 { "tokens" : [ { "token" : "this" , "start_offset" : 3 , "end_offset" : 7 , "type" : "<ALPHANUM>" , "position" : 0 } , { "token" : "is" , "start_offset" : 8 , "end_offset" : 10 , "type" : "<ALPHANUM>" , "position" : 1 } , { "token" : "a" , "start_offset" : 11 , "end_offset" : 12 , "type" : "<ALPHANUM>" , "position" : 2 } , { "token" : "text" , "start_offset" : 16 , "end_offset" : 28 , "type" : "<ALPHANUM>" , "position" : 3 } ] }
分词使用说明 分词会在如下两个时机使用:
创建或更新文档时(Index Time ) ,会对相应的文档进行分词处理 查询时( Search Time ) ,会对查询语句进行分词 索引时分词 索引时分词是通过配置Index Mapping中每个字段的analyzer属性实现的如下:不指定分词时,使用默认standard
查询时分词 查询时分词的指定方式有如下几种:
查询的时候通过analyzer指定分词器 通过index mapping设置search_analyzer实现
实例1:我们做一个查询,我们试图通过搜索 message2 这个关键词来搜索这个文档
request 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 GET test_index1/doc/1 POST test_index1/doc/1 { "message": "this Is a Message" } POST test_index1/doc/2 { "message": "this Is a Message2" } POST test_index1/_search { "query": { "match": { "message": { "query": "message2", "analyzer": "standard" } } } }
返回结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "took" : 1 , "timed_out" : false , "_shards" : { "total" : 5 , "successful" : 5 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : 1 , "max_score" : 0.2876821 , "hits" : [ { "_index" : "test_index1" , "_type" : "doc" , "_id" : "2" , "_score" : 0.2876821 , "_source" : { "message" : "this Is a Message2" } } ] } }
查询时使用自定义分词器
request 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 DELETE test_index1 PUT test_index1 { "settings": { "analysis": { "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "standard", "char_filter": [ "html_strip" ], "filter": [ "lowercase", "asciifolding" ] } } } } } POST test_index1/doc/1 { "message": "<a>this Is a <b>Message</b></a>" } POST test_index1/doc/2 { "message": "<a>this Is a <b>Message2</b></a>" } POST test_index1/_search { "query": { "match": { "message": { "query": "Message2", "analyzer": "my_custom_analyzer" } } } }
分词建议 明确字段是否需要分词,不需要分词的字段就将type设置为keyword ,可以节省空间和提高写性能 善用_analyze API ,查看文档的具体分词结果 动手测试 分词使用分析 创建自定义分词
request 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 DELETE test_index PUT test_index { "settings": { "analysis": { "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "standard", "char_filter": [ "html_strip" ], "filter": [ "lowercase", "asciifolding" ] } } } } }
插入数据:
request 1 2 3 4 POST test_index/doc/1 { "message": "<a>This is a <b>Text</b></a>" }
分词检索:
request 1 2 3 4 5 6 7 8 9 10 11 POST test_index/_search { "query": { "match": { "message": { "query": "<div>this is</div>", "analyzer": "my_custom_analyzer" } } } }
返回结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "took" : 0 , "timed_out" : false , "_shards" : { "total" : 5 , "successful" : 5 , "skipped" : 0 , "failed" : 0 } , "hits" : { "total" : 1 , "max_score" : 0.5753642 , "hits" : [ { "_index" : "test_index" , "_type" : "doc" , "_id" : "1" , "_score" : 0.5753642 , "_source" : { "message" : "<a>This is a <b>Text</b></a>" } } ] } }
为什么会返回这条记录,我们使用分词分析来分析原因:
request 1 2 3 4 5 POST test_index/_analyze { "analyzer": "my_custom_analyzer", "text": "<a>This is a <b>Text</b></a>" }
Result:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 { "tokens" : [ { "token" : "this" , "start_offset" : 3 , "end_offset" : 7 , "type" : "<ALPHANUM>" , "position" : 0 } , { "token" : "is" , "start_offset" : 8 , "end_offset" : 10 , "type" : "<ALPHANUM>" , "position" : 1 } , { "token" : "a" , "start_offset" : 11 , "end_offset" : 12 , "type" : "<ALPHANUM>" , "position" : 2 } , { "token" : "text" , "start_offset" : 16 , "end_offset" : 28 , "type" : "<ALPHANUM>" , "position" : 3 } ] }
由上面的结果看一看出我们自定义的分词将<a>This is a <b>Text</b></a> 分成了this,is,a,text
我们由前面的分词器的解释可了解到lowercase将元文本规范化为小写,asciifolding 类型的词元过滤器,将不在前127个ASCII字符(“基本拉丁文”Unicode块)中的字母,数字和符号Unicode字符转换为ASCII等效项(如果存在)。<div>this is<div>首先html标签被过滤掉,所以不管什么标签都可以满足条件,其次