单机版Redis问题
- 机器故障需要做数据手动迁移
- 容量瓶颈
- QPS瓶颈
引入正题
前面列出的容量瓶颈和QPS瓶颈是redis分布式要解决的问题,本篇还是主要解决
redis怎么实现高可用,机器故障的问题
主从复制介绍
作用:
- 流量分流和负载均衡
- 提供多个数据分布
- 扩展redis读性能
简单总结
- 一个master可以有多个slave
- 一个slave只能有一个master
- 数据流向是单向的,master到slave
主从复制操作
master节点:
1 | cp ${redis_src}/redis.conf redis-6379.conf |
改动项:
1 | daemonize yes |
slave节点:
1 | cp ${redis_src}/redis.conf redis-6380.conf |
改动项:
1 | daemonize yes |
启动:
1 | redis-server 6379.conf |
检查主从状态:
1 | redis-cli |
runid和复制偏移量
runid
redis每次启动后都会随机生成一个runid执行:
1 | redis-cli -p 6379 info server |grep run |
redis每次重启runid会发生变化,redis从节点每次会检测主节点runid变化来进行一次全量复制
偏移量
主节点和从节点都会记录执行一条命令时数据写入的字节数,当偏移量达到一致时,数据才会同步完成
全量复制
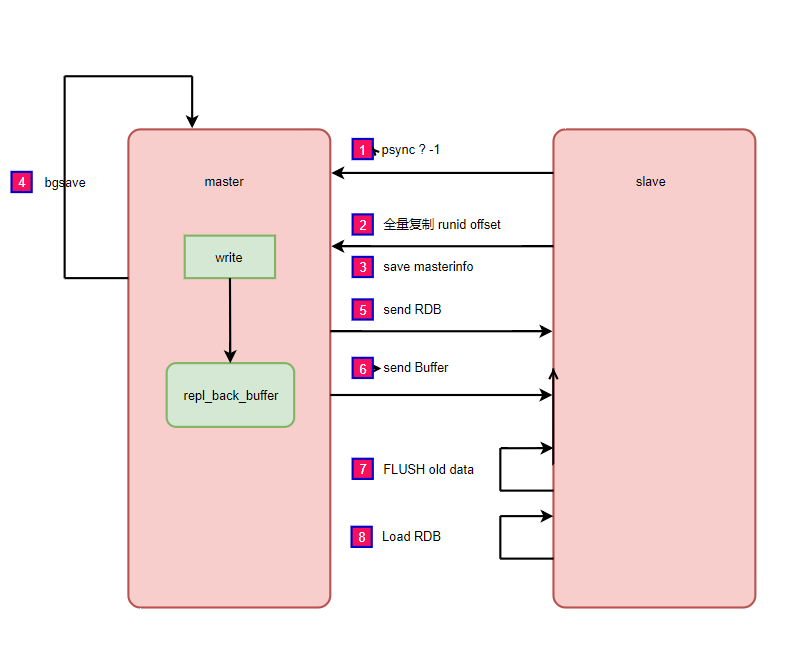
全量复制开销
- bgsave时间
- RDB文件网络传输时间
- 从节点清空数据时间
- 从节点加载RDB时间
- 如果配置AOF开启会有AOF重写时间
部分复制
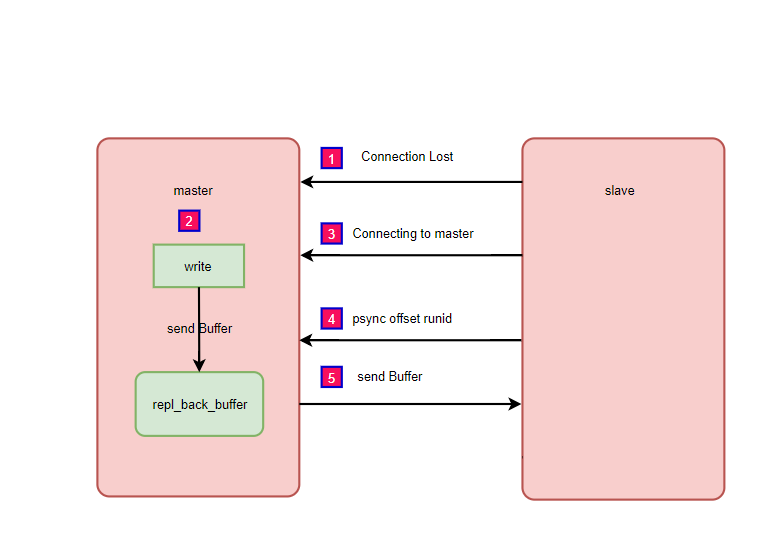
开发运维中的问题
规避全量复制:
1:第一次全量复制
- 问题:第一次不可避免
- 解决:小主节点,低峰
2:节点运行ID不匹配
- 问题:主节点重启runid变化
- 解决:故障转移,例如哨兵或集群
3:复制积压缓冲区不足
- 问题:网络中断,部分复制无法满足
- 解决:增大复制缓冲区配置rel_backlog_size
规避复制风暴:
1:单主节点复制风暴
- 问题:主节点重启,多从节点复制
- 解决:更换复制拓扑(树形架构)
1:单机器复制风暴
- 问题:机器宕机后,大量全量复制
- 解决:主节点分散多机器