故障发现
通过ping/pong消息实现故障发现,不依赖sentinel
主观下线
定义:某个节点认为另外一个节点不可用“偏见”
主观下线流程: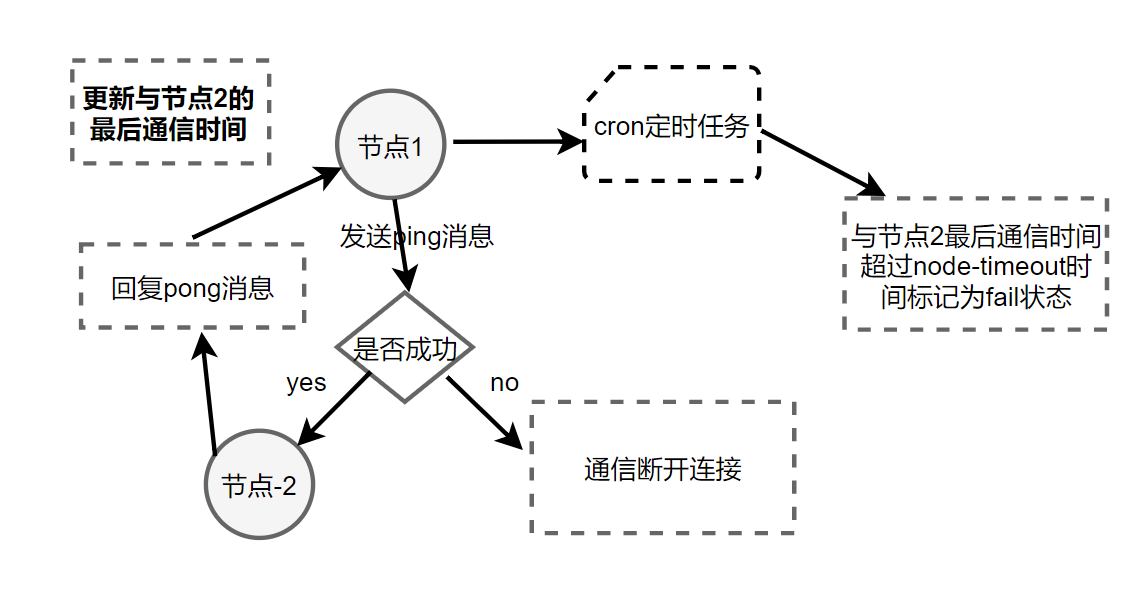
客观下线
定义:当半数以上持有槽的主节点都标记某节点主观下线
客观下线流程: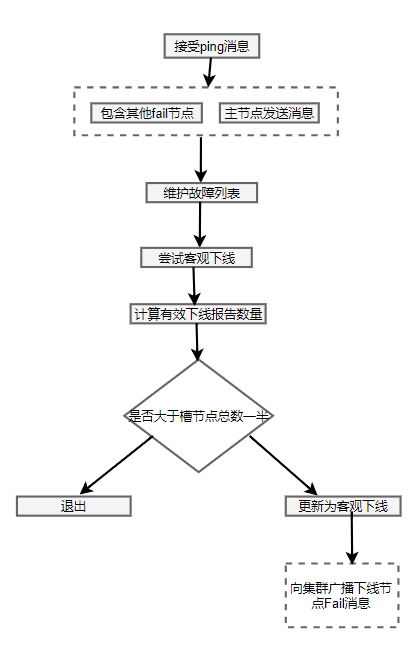
故障恢复
资格检查
- 每个从节点检查与故障节点的断线时间
- 超过cluster-node-timeout*cluster-slave-validity-factor取消资格
- cluster-slave-validity-factor:默认为10
准备选举时间
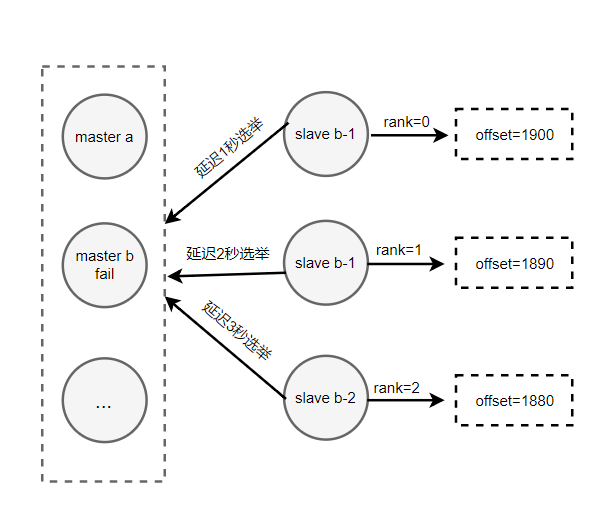
选举投票
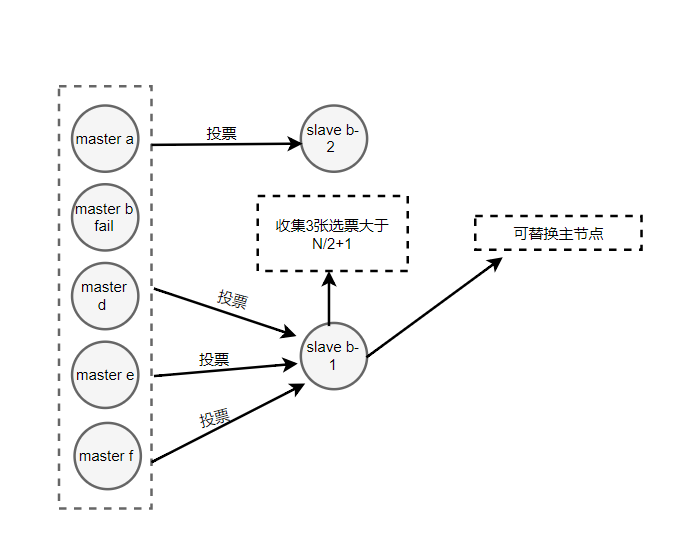
替换主节点
- 当前从节点复制变为主节点。(slaveof no one)
- 执行clusterDelSlot撤销故障主节点负责的槽,并执行clusterAddSlot
把这些槽分配给自己 - 向群广播自己的pong消息,表明已替换了故障从节点
redis cluster 开发常见问题
集群完整性
cluster-require-full-coverage默认为yes
问题:
- 集群中16384个槽全部可用,保证完整性
- 节点故障转移或正在转移
大多数业务无法容忍,建议设置为no当其中一台机器发生故障,此时集群状态不可用,不可以set ket,不建议设置为yes
宽带消耗
官方建议:1000个节点
- 消息频率 节点发现和节点最后通信时间超过cluster-node-timeout/2时会发送ping消息
- 消息数据量 slots数据组(2k)和整个集群1/10的状态数据(10个节点状态数据约1k)
- 节点部署机器规模 分布机器越多且每台机器划分的节点越均匀,整体的可用带宽越高
例子:200个节点,20个物理机器(每台10个节点)
cluster-node-timeout=15000 ping/pong带宽约25MB
cluster-node-timeout=20000 ping/pong带低于15MB
优化
- 避免多业务使用多集群,大业务可以多集群
- cluster-node-timeout 带宽和故障转移速度的均衡
- 尽量均匀分配多个机器,保证带宽
PUB/SUB广播
问题:publish在集群每个节点广播:加重带宽
解决:单独走一套redis sentinel
数据倾斜
数据倾斜:内存不均匀
节点和槽分配不均匀
不同槽对应键值数差异大
- 可能存在has_tag
- cluster countkeysinslot {slot}获取槽对应键值个数
包含bigkey
- 例如大字符串,几百万元素的hash,set等
- 从节点,redis-cli –bigkeys
- 优化数据结构,拆分key
内存相关配置不一致
- hash-max-ziplist-value, set-max-intset-entries等
请求倾斜:key热点重要的key或者bigkey
优化:
- 避免big_key
- 热键不要使用hash_tag(避免落在一个节点)
- 当一致性不高时可以使用本地缓存+MQ
读写分离
只读连接:集群模式的从节点不接受任何读写请求
- 重定向到负责槽的主节点
- readonly命令可以读:连接级的命令
读写分离:更加复杂 - 复制延迟,从节点故障,读取过期数据
- 修改客户端:cluster slaves {nodeid}
数据迁移
官方工具:redis-trib.rb import
- 只能从单机迁移到集群
- 不支持在线迁移,source需要停写
- 不支持断点续传
- 单线程迁移,影响速度
在线迁移:
唯品会:redis-migrate-tool
豌豆荚:redis-port
集群VS单机
集群限制
- key批量操作限制
- key事物和lua支持有限,操作的key必须在同一个节点
- key是数据分区的最小粒度:不支持bigkey分区
- 不支持多个数据库:集群模式下只有一个db0
- 复制只支持一层,不支持树形
- Redis Cluster: 满足容量和性能的扩展性:很多业务不需要
- 很多场景Redis Sentinel足够好