呼唤集群
当系统应用需要有更大容量和QPS的支撑,此时就需要采用的集群的方式,也可以简单理解为加机器
数据分区:
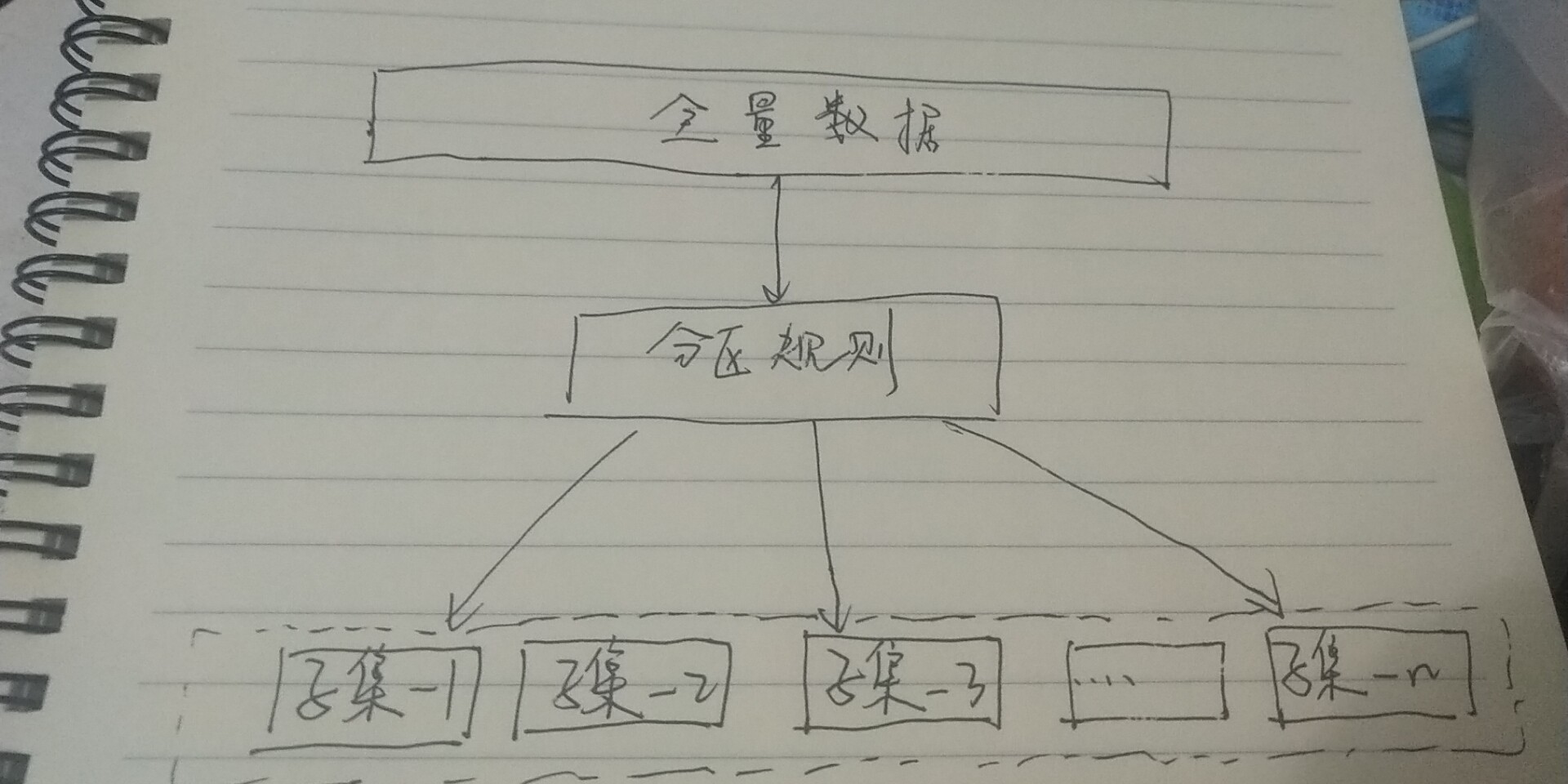
分布方式
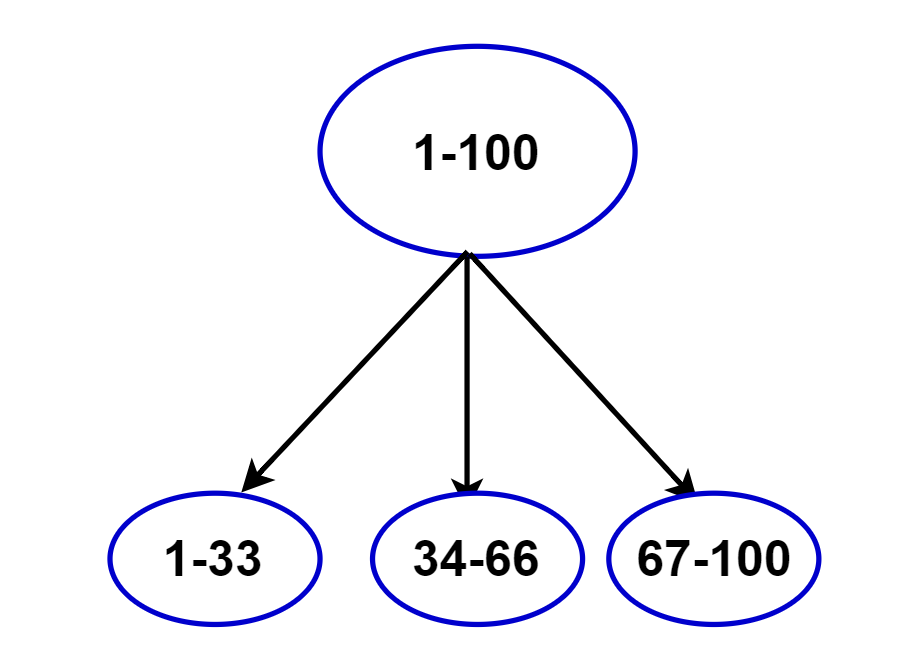
顺序分布
哈希分布
- 节点取余
- 一致性hash
- 虚拟槽分区
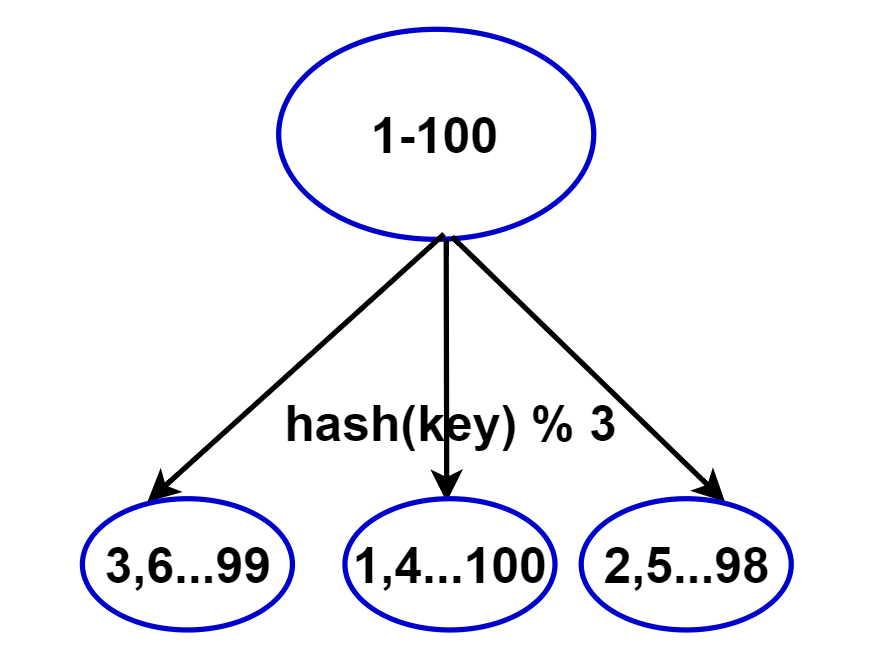
节点取余
- 客户端分片: 哈希+取余
- 节点伸缩: 数据节点关系变化,导致数据迁移
- 迁移数量和添加节点数量相关:建议翻倍扩容
一致性hash
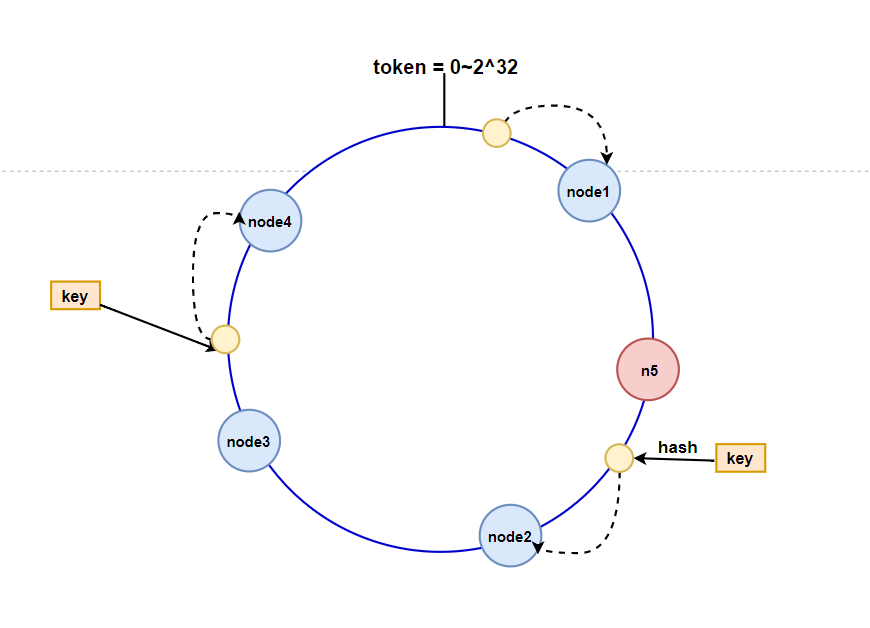
一致性hash扩容
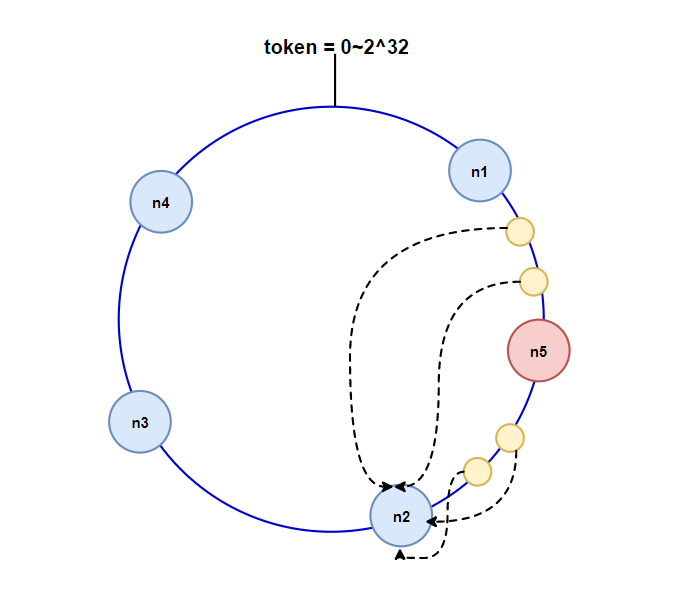
- 客户端分片:哈希+顺时针(优化取余)
- 节点伸缩:只影响临近节点,但是还是有数据迁移
- 翻倍伸缩:保证最小迁移数据和负载均衡
虚拟槽分布
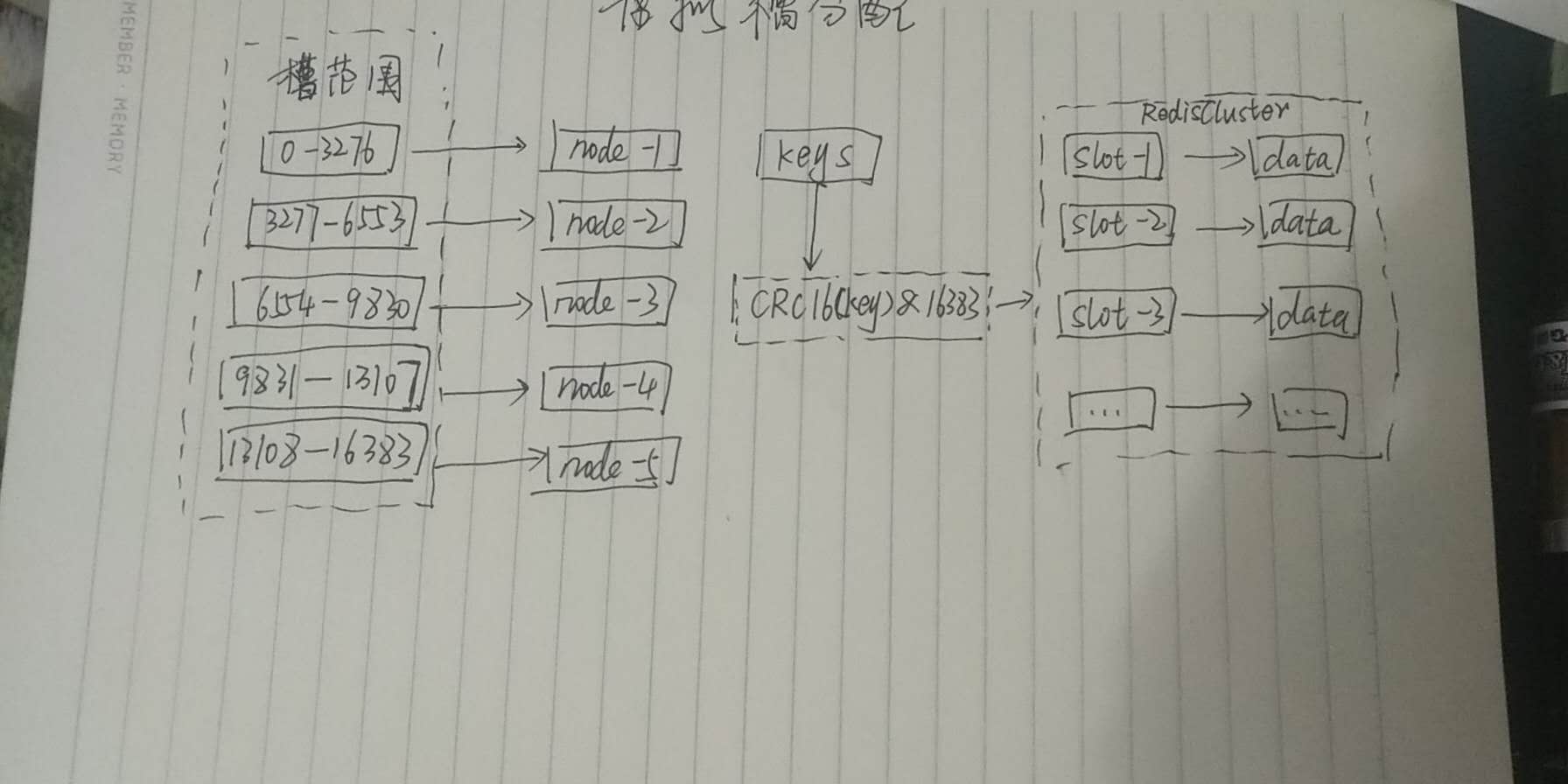
- 预设虚拟槽:每个槽映射一个数据子集,一般比节点数大
- 良好的hash函数:如crc16
- 服务端管理节点,槽,数据:例如redis cluster
对比
| 分布方式 | 特点 | 典型产品 |
|---|---|---|
| 哈希分布 | 数据分散度高 key,value分布业务无关 无法顺序访问 支持批量操作 | 一致性hash memcache redis cluster 其它缓存产品 |
| 顺序分布 | 数据分散度易倾斜 key,value业务相关 可顺序访问 支持批量操作 | BigTable HBase |
架构
- 节点
- meet
- 指派槽
- 复制
特性:
- 复制
- 分片
- 高可用
安装
原生安装
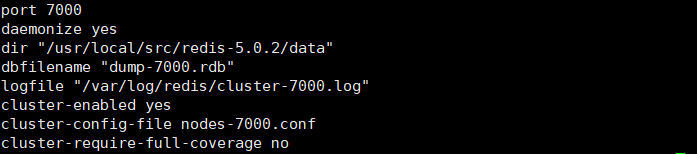
1: 配置开启节点:
1 | port{$port} |
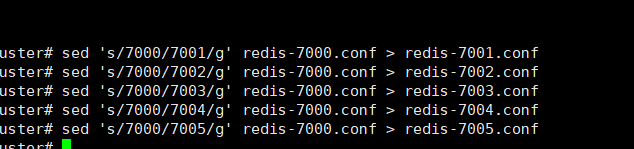
批量生成配置文件:
执行:
1 | redis-server redis-7000.conf |

2: meet
cluster meet ip port
1 | redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7001 |
先进行7000和7001的握手

发现7000和7001已经完成握手,继续meet其他的节点
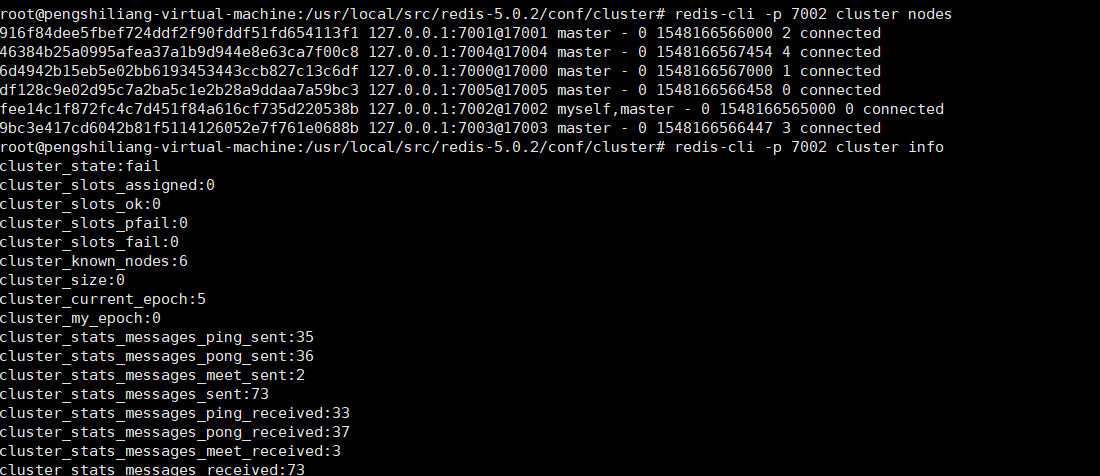
此时执行cluster nodes和cluster info均发现6个节点相互关联,证明已经握手成功
3: 指派槽
cluster addslots slot [slot…]
由于一共要分配16384个槽,所以需要借助脚本去分配槽
1 | start=$1 |
我们要配置的是三主三从,所以要把16384三等分
1 | 0-5461 7000 5462-10922 7001 10923-16383 7002 |
执行以下命令:
1 | sh addslots.sh 0 5461 7000 |
查看槽分配状态
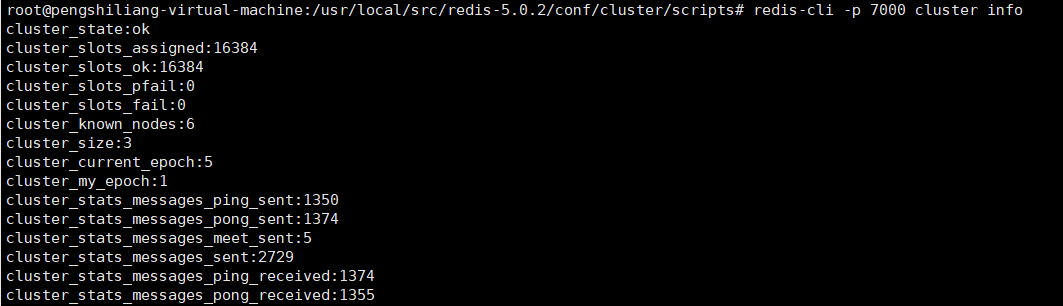

此时发现16384个槽确实已经分配完毕,槽分配完毕
4: 主从
cluster replicate node-id
给7003分配到master7000主节点上:
1 | redis-cli -p 7003 cluster replicate 6d4942b15eb5e02bb6193453443ccb827c13c6df |
主从分配结果:
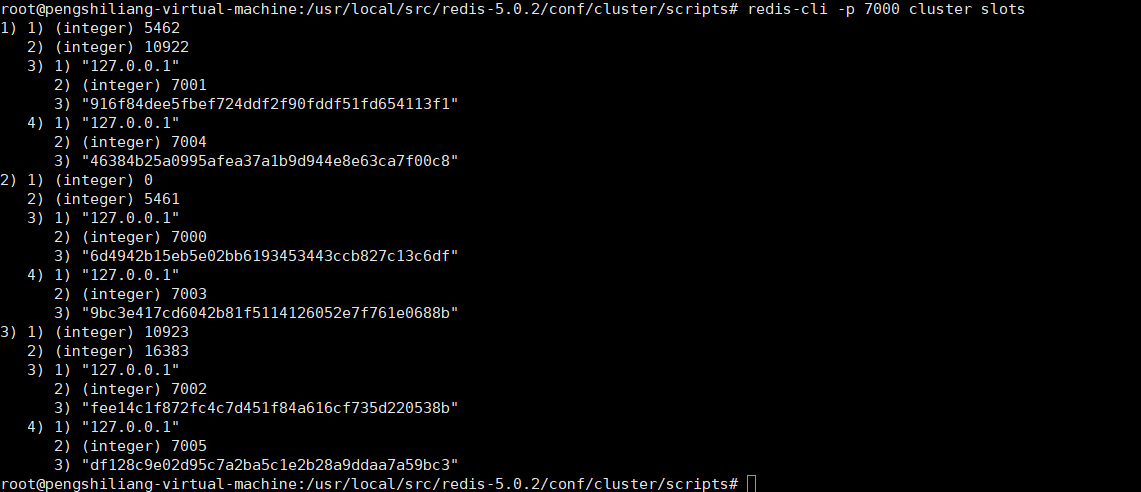
官方工具
由于原生安装过程比较麻烦,又容易出错,所以正常的生产环境使用官方工具安装,但是掌握原生安装的方式更容易让我们理解集群分配的原理
ruby环境准备
- 下载编译安装ruby
- 安装rubygem redis
- 安装redis-trib.rb
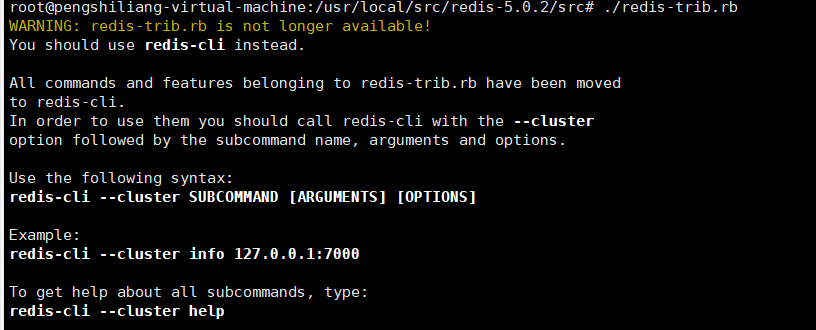
1: 配置开启节点:
1 | port{$port} |
执行:
1 | redis-server redis-7000.conf |
2: 集群创建
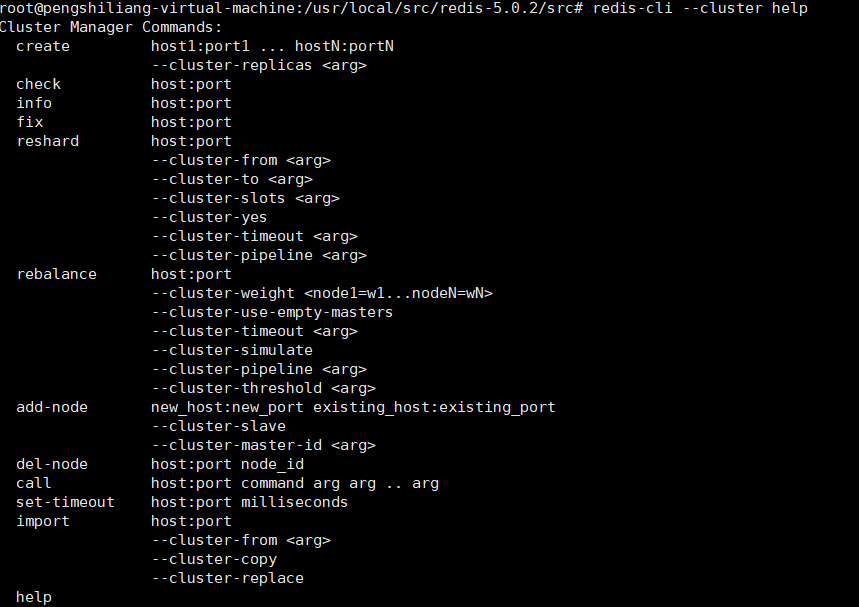
1 | //1 表示1个主节点分配1个从节点 |
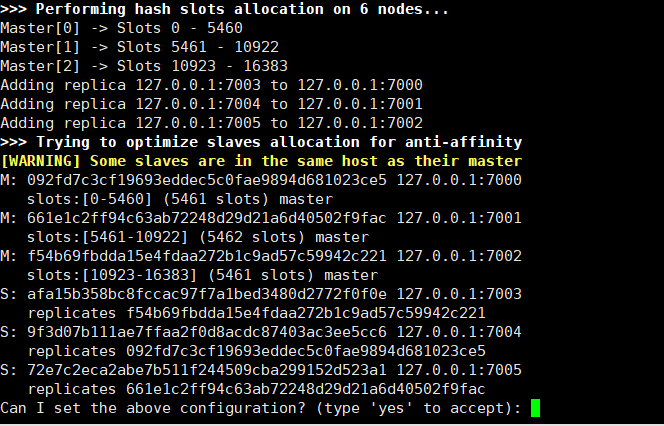
上图分别展示了槽分配,主从和节点信息,符合预期执行yes即可
分配成功信息:
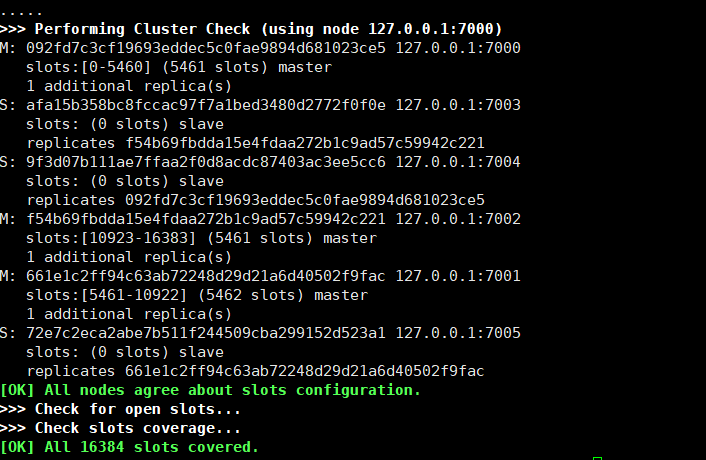
集群验证:

当然如果维护上百台集群显然也不是最好的方式,可以借助或构建云平台来管理集群